(cross-posted from Into Thin Air)
On March 9th, 2017 I gave a talk at our office in Denver about an architectural approach we’re taking to modularize our codebase. Of note, this approach is experimental and is not widely implemented at Gusto.
Sixty or so Denver-based engineers attended, and we had a great Q&A (and beer-drinking) session afterward.
Here’s the talk in written form:

I’ve been doing this for a while.

“Monolithic” codebases are ones where all of the source code gets contributed to a single repository, which bloats over time. In order to understand how this happens, it’s important to contemplate what’s at stake for an early-stage company. Gusto started in late 2011.

We were called “ZenPayroll” back then. And there was no certainty that the company would be successful. Scalability lacks primacy in a company’s early days. Instead, the company needs to iterate quickly and prove that is solving actual business problems with its product and becoming “default-alive.”
But the byproduct of striving to reach the default-alive state is that code piles up in a single repository. Now, in early 2017, the “zenpayroll” repository has signs of bloat.
And this manifests in several ways. Gusto’s Engineering, Product, and Design team is divided into five product areas. While “Gusto” now comprises dozens of independent applications, much of the code for these product areas exists within the same repository. And no one can deploy code to Production unless every team’s tests pass.
Sometimes, teams introduce “flaky tests” — tests that fail under certain conditions (such as a date change from 12/31 to 1/1). And one team’s “flaky” test can hold up the deploy pipeline for a distant feature.
Plus, it takes several minutes to run all of the tests within this repository. This is a long time for a developer to wait to understand if her commits play nicely with everyone else’s code.

Further, we see features from a given sub-domain littered throughout the codebase.

For example, one team works to synchronize Gusto data with Salesforce. Our Sales and Marketing teams rely on this data to manage leads generated on our software. The word “Salesforce” appears thousands of times throughout our main repository.
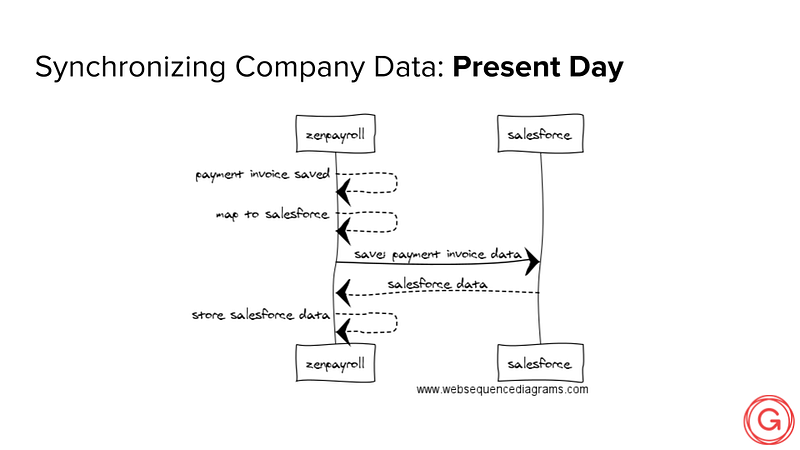
Let’s understand how “zenpayroll” synchronizes with Salesforce. Every month we issue payment invoices to our customers. This data is used, in part, by our Sales team to calculate commissions within that system.
So, when a payment invoice is created or changed, we synchronize it with Salesforce through their API.
We then store Salesforce IDs to help with de-duplication.
“Zenpayroll” knows a lot about Salesforce…
class PaymentInvoice < ActiveRecord::Base
...
include Salesforce2::RealtimeSynchronizable
include Salesforce2::Mapping::PaymentInvoice
...
end
The PaymentInvoice class knows about Salesforce…
module Salesforce2::RealtimeSynchronizable
extend ActiveSupport::Concern
include Salesforce2::Synchronizable
included do
after_save :trigger_salesforce_synchronization, if: :synchronization_enabled?
before_destroy :trigger_salesforce_destroy, if: :synchronization_enabled?
end
private
def trigger_salesforce_synchronization
Salesforce2::Manager.perform_async(self.class, self.id)
end
def trigger_salesforce_destroy
Salesforce2::Manager.perform_async(self.class, self.salesforce_key, :remove)
end
end
And we have a module, that gets “mixed in” to the PaymentInvoice class in order to do “Salesforce-y” things.
module Salesforce2
class Manager
include Sidekiq::Worker
...
def perform(synchronizable_class, synchronizable_id, operation = :synchronize)
synchronizable_class = Object.const_get(synchronizable_class) if synchronizable_class.is_a?(String)
if (:remove == operation)
remove(synchronizable_class, synchronizable_id)
elsif (:synchronize == operation)
return unless ((synchronizable = define_synchronizable(synchronizable_class, synchronizable_id)).present?)
synchronize(synchronizable)
end
end
..
end
end
And then a Manager class gets involved, whose purpose is to add Salesforce business logic to the API call…
module Salesforce2
module Mapping
module Fields
def salesforce_fields(salesforce_object_type, params = {})
method = "salesforce_#{salesforce_object_type}_fields"
self.send(method,params.merge({ has_been_synchronized: self.has_been_synchronized? }))
end
end
end
end
And, we map PaymentInvoice attributes to Salesforce fields…

Yes, it’s a lot of Salesforce-related code within the “zenpayroll” codebase.

In an ideal world, “zenpayroll” knows nothing about Salesforce. This might help free it up to focus exclusively on its domain.

https://martinfowler.com/articles/201701-event-driven.html
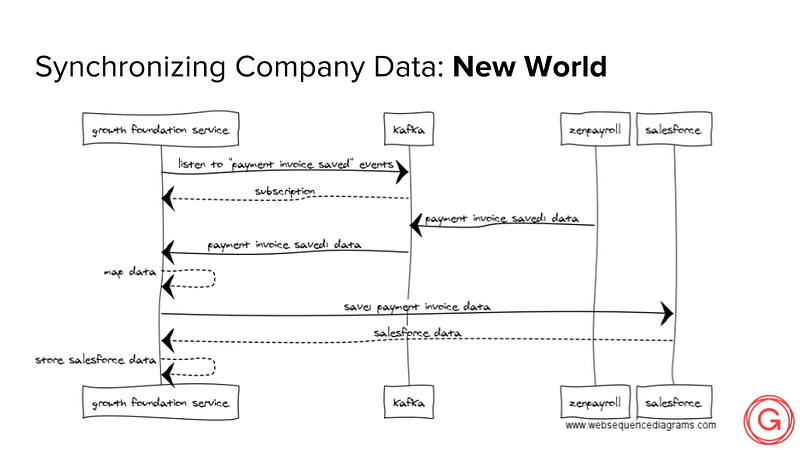
In this New World, “zenpayroll” broadcasts changes to its domain. Interested services, such as our “Growth Foundation Service,” can subscribe to these broadcasted events, and do work with them.
What’s interesting about this pattern is that event data is carried with the broadcast, so there’s no need for a service to query “zenpayroll” for supporting data.
Further, “zenpayroll” necessarily has no idea that its payment invoice data will be picked up by the Growth Foundation Service and synchronized with Salesforce. It merely informed the world that a payment invoice record was changed.

Kafka is to events what air is to sound waves — it’s the medium through which data is transported.
We experimented with other messaging systems, such as Amazon SQS, but went with Kafka out of FIFO considerations (at the time, SQS could not guarantee “first in, first out” message delivery).
First, we created a gem that would provide all of the plumbing required for our “zenpayroll” Rails project to transmit events to Kafka.
After including the gem, we add a simple mixin to an ActiveRecord class to publish events.
publish_to_kafka 'company_migration', async: true, template: 'company_migrations/external'
It was inspired by the paperclip gem, and we can see it in use here on the PaymentInvoice class within the “zenpayroll” repository.
Instead of including all of that “Salesforce-y” code within the class, we simply publish a message to Kafka indicating there’s been an update to the object. And that’s made possible by including this “publish_to_kafka” mixin, which hooks into the Rails callback pipeline to do its broadcasting.
The Kafka payload is JSON.
(note, the KafkaRails gem is only available inside Gusto…for now.)
As this architecture is experimental, we decided to use the Heroku Kafka plugin to host our Kafka (and Zookeeper) instance.
class PaymentInvoiceService < Service
TOPIC = 'zenpayroll.payment_invoice'
def initialize
super(TOPIC, [Publishers::HerokuConnectPublisher])
end
def on_receive(topic, message)
Rails.logger.info(JSON.pretty_generate(message))
end
end
Here’s a basic example of the PaymentInvoiceService microservice, part of the broader Growth Foundation Service depicted in the event sequence diagram, that subscribes to “zenpayroll” PaymentInvoice events.
This example is pretty simple, as it merely logs its payload to the console and log file.


If a given service is expecting a certain JSON structure, and said structure changes, the service is compromised. Payload changes need to be managed carefully.

While Kafka helps with “first in, first out” processing order, it’s still not guaranteed. This is especially so in a situation where, for example, a user makes changes to a payment invoice in rapid succession on the UI, but the system publishes them out of order. The Growth Foundation Service could update Salesforce with outdated data in this situation.

Our implementation of “Event-Carried State Transfer” is unidirectional and doesn’t work for systems requiring synchronous communication, or acknowledgement that a given message has been processed.

And, of course, it’s much harder to debug a distributed system than one that’s monolithic.


Code ownership has much clearer team boundaries. If the Growth Foundation Service produces an error, we know which team is responsible for it.

We can use the Event-Carried State Transfer pattern to update multiple distributed systems with one message. For example, we might consider concurrently synchronizing Salesforce and our data warehouse with a single message.

As the “zenpayroll” codebase shrinks, tests run faster. And tests within new services we create will run quickly, too.
