Here at Gusto we are focused on creating a data-informed culture. For us, this means that we apply our values, principles, and experiences when we gather, analyze, and incorporate data into our decision-making.
The Data team is responsible for building our data-informed culture. We curate and develop tools using the data created by our over 40,000 customers to help us grow efficiently, control risk and avoid fraud, and build product features that help Gusto’s customers become data-informed too.
How did the Data team begin?
By early 2015, demand was growing internally for access to data. At the time this demand was satisfied by product managers and engineers running their own ad-hoc SQL scripts on production databases and operations teams generating reporting via their own tools. We realized that we needed to build a team that would bring all of these disparate sources together. That way, we could empower the whole company to make more effective data-informed decisions.
Once we decided to invest in being data-informed, we had to choose whether to focus on growing a data science team to get value out of the data or a data engineering team that could create the foundational infrastructure first. After internal discussions and speaking to friends at other companies who have gone through this process, we came to the conclusion that it was most important to lay the right foundation first by developing a warehouse that could provide a single source of reliable and consistent data. This was the right move for us even if it meant fewer quick wins because it would enable future data scientists and analysts to more efficiently leverage their core competencies - building models and generating insights.
Over the past year we have replicated and piped all of our major data sources into a single warehouse that teams across the company can access. Our Data team is at ten members and growing, and as we’ve grown we’ve also clarified roles and responsibilities. The Data Science & Engineering team consists of engineers and data scientists, with engineering focusing on developing and maintaining data infrastructure and tools while data science builds predictive models and statistical tools. The Data Analytics team works closely with people across the company to make sure they have access to the most up-to-date insights relevant to their work, whether that’s helping our Care team manage their queue or building a new core dashboard for our Growth team members.
The what and why of our infrastructure
We’ve gone through a couple of iterations of our data platform and have currently settled on the the tools and structure in the diagram below:
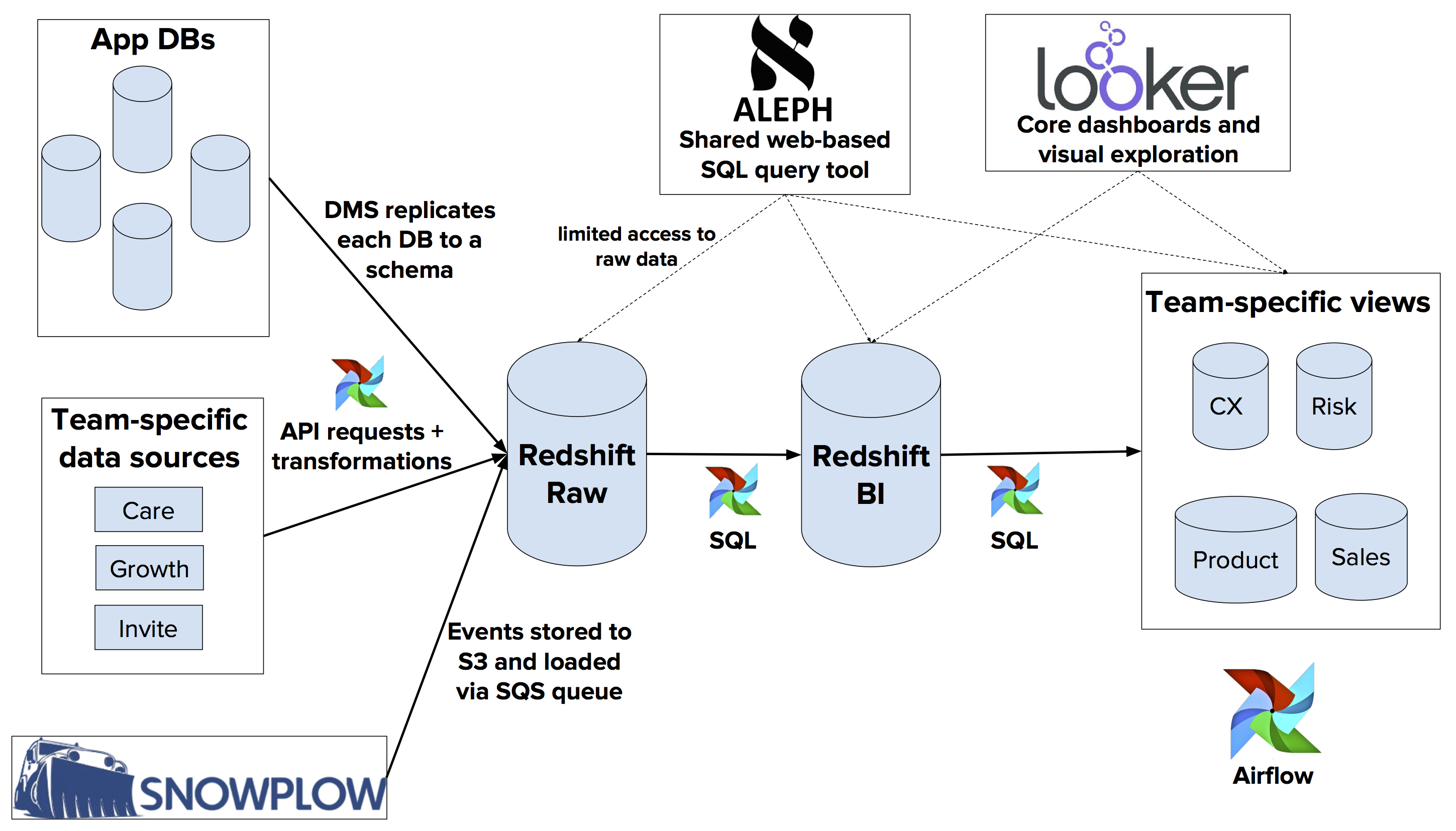
Tools we use
We prefer to use open source tools where possible (marked with a *).
- Our analytical database is an AWS Redshift cluster, with S3 as our underlying data lake
- Amazon’s Database Migration Service replicates our production app databases to individual schemas in Redshift
- Apache Airflow* orchestrates our ETLs. We use Airflow to support a variety of tasks, such as:
- Ingesting data from 3rd party vendor APIs
- SQL statements that create higher level views (more on this later)
- Testing and QA tasks to alert us of faulty logic and downstream changes from our production apps so that we don’t propagate bad data to our end users
- Snowplow* for event tracking in our apps, which supports easy integration into Redshift out of the box
- Looker as a BI front-end that teams throughout the company can use to explore data and build core dashboards
- Aleph* as a shared repository for ad-hoc SQL queries and results
Structure of our data warehouse
At the lowest level, we have our raw replicated data sources - production app tables, events and third party integrations. While our apps automatically encrypt the most sensitive pieces of information like bank account numbers, EINs and SSNs, access to these schemas is strictly controlled because they contain personally identifiable information (PII).
In the middle, we have our BI tables - user-friendly versions of the data in our apps and third-party data sources, denormalized for easier analysis. We also separate PII (personally identifiable information) into a different schema and control access to it.
At the highest level, we have team-specific views - these are joins and rollups of multiple BI tables that specific teams use to drive core dashboards and look at on a daily basis.
As a fast-growing SaaS business we don’t have major data scaling issues (yet!), but this actually provides us with some unique advantages. For example, we’ve found that when an analyst needs a new ETL (extract-tranfsorm-load) task for a project they’re working on, it’s more efficient for the whole team if they can write it themselves rather than having to hand it off to an engineer. Since the raw tables are available in Redshift to our ETL application, when an analyst wants to make a new BI table to expose new data sources to end users, they can simply find the relevant tables and columns in the raw tables, write queries to build the tables they need as part of an Airflow task, and expose them in Looker for use in dashboards and further analysis. Direct access to raw data is strictly controlled.
Where we’re going
The newest data investment for us is in data science. Gusto processes billions of dollars in payroll each year and adds many new customers every day. This means we need to have amazing teams and great software to keep everything humming, and we’re lucky to have both. We think we can make things run even smoother and provide more value to our customers by incorporating predictive models and statistical tools into our teams’ workflows and into our own product. Here are a few of the specific areas we’re focusing on:
- Stopping fraudsters in their tracks in partnership with our Risk team
- Helping Gusto grow efficiently by focusing our efforts on businesses who are likely to get the most benefits out of our product today
- Leveraging insights from our payroll and benefits data (like in our recent Minimum Wage Report), so we can help our customers get more meaning out of the information we have.
As both our team and data grow over the coming months and years, we want to continue to make it easier for our analysts and scientists to get the data they need, and for engineers to turn these insights into amazing products and services for our team and our customers. We’re mindful that in order to do this our tools and pipelines will need to change as we grow, as will the way we organize ourselves.
We’re looking for data scientists and engineers to join us, so if these problems sound interesting to you, take a look at our job openings!
