In today's data-driven world, organizations are recognizing the value of applying analytics to HR data. By analyzing information about individuals, businesses can gain crucial insights to improve talent development, enhance employee experiences, and streamline human resources processes. The application of analytics to people data empowers organizations to harness the full potential of their most important asset: their people.
HR/People data contains information about employees of the company and the candidate pipelines. The information is highly sensitive with fields containing attributes such as race/ethnicity, sexual orientation etc. Hence, People Insights Infrastructure is built w/ Security as the focal point.
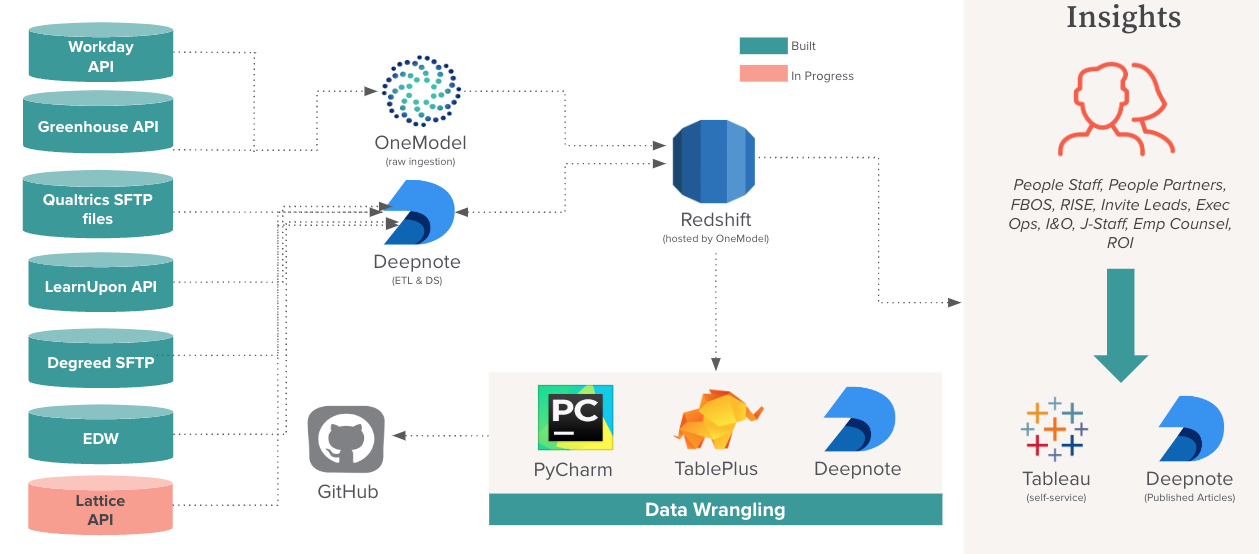
Gusto uses Workday as HRIS, Greenhouse as the choice for ATS (Applicant Tracking System), Qualtrics as the survey tool, Degreed and LearnUpon for learning and development.
To help with this, we have adopted One Model's People Data Cloud platform, for its capabilities in extracting and modeling HR data sources. It is used specifically for its Greenhouse and Workday integration.
Deepnote is utilized for end-to-end data pipelines (ELTs) involving Degreed, LearnUpon, and Qualtrics. We also create denormalized tables on top of OneModels output schema, stored in a Redshift cluster hosted on OneModels AWS account. Tableau is employed as the front-end to develop insightful dashboards.
Workday Integration [Employee data]:
Application of employee data:
- Workforce planning dashboard: helps in headcount planning by utilizing the employee hiring, terminations and movement. Integration of data points - employees who have accepted the offer but have a future start date -
Accepted Not StartedandOpen RequisitionsacrossMoMaids in a single source of truth for workforce planning and forecasting. - Data Feeds to Finance partners helps them run forecasts on the cost of talent($).
- Data Science:
- Study, develop and publish research on drivers of employee turnover, performance and promotion.
- Publish internal research around pay equity and adverse impact.
- Internal and external reporting requirements of any RISE+ parameter combinations
- Regulatory reporting:
Technical Architecture:
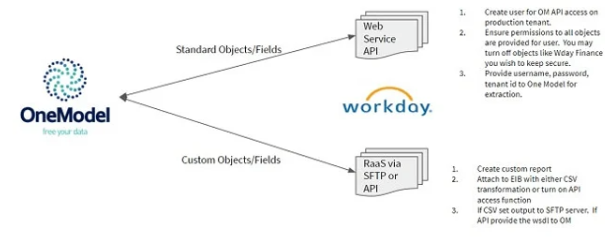
Workday is built with an object-oriented approach. Standard objects can be queried via direct API calls and custom objects via Reporting-as-a Service (RaaS). RaaS is a feature that exposes reports as web service.
Greenhouse Integration [Candidate & Application data]:
Application/Business Impact:
- Talent lifecycle: understanding the lifecycle of a candidate applying for a role at Gusto at each stage : application → interviewing → offer → conversion to an employee in workday.
- Clean and robust recruiting data helps us inform the common KPIs which provides us strategic insights on sourcing, offers and overall pipeline health. Thus, able to calculate recruiting efficiency and pipeline health.
Technical Architecture:
Greenhouse connector (combination of API calls) is available within OneModel to extract all the necessary endpoints.
For modeling the data within One Model, we are using an Extract-Load-Transform (ELT) approach where modeled tables are stored in One Schema. Then we are able to build denormalized/reporting tables by writing business logic and transformation on top of One schema to build people insights schema, which is the source of truth for data science, analytics reporting & tableau data sources.
Security enhancements:
- Full access to the People Data Warehouse (PDW) is restricted to the People Insights team and the OneModel vendor and is IP restricted
- External reporting teams have a service account to Redshift to pull non-sensitive data from the public database schema. [Limited access]
- PGP encryption service helps to encrypt the outbound data feeds.
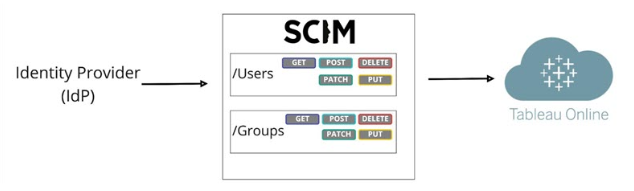
For visualization and building scalable dashboards, we utilize Tableau. In Tableau, we have automated managing the user permissions by setting up user groups in workday (source system), which flows through Okta (for authentication) to reach Azure Active Directory (Identity Provider). Tableau server syncs groups every ~30 min.
This helps our team to directly leverage the groups in Tableau and immune us against the possibility of manual errors.
Ex: Transfer scenario: if an employee moves from People to Product, they would need to be adjusted manually within a group in tableau for the access level. This has the risk of unauthorized access.
These groups also serve as google groups within Gmail. This helps us be in sync with the single definition of each group.
Idiosyncratic scenarios: Evergreen requisitions in Greenhouse
Each organization has evergreen requisitions (ex: software engineering role for tech company) which runs throughout the year. However, there is no capability of connecting these roles in Greenhouse ←→ Workday.
Imagine, a candidate interviewing for multiple roles (at least one of them being evergreen)
reaching the offer stage for one of them in the greenhouse. At this point, we have multiple applications per candidate.
But, we don’t know which one to use for calculating funnel metrics (such as pass-through rate) if both applications with evergreen req are not mapped to workday. This results in skewed data points.
In collaboration with OneModel, we have built an algorithm that inferences the headcount requisition which are disconnected from application with ~94% accuracy.
Integration for following data sources are written end-to-end in Deepnote, which provides us the ability to have a separate account for people insights team. This helps us to keep our codebase and data private. Key feature which helps us in data pipelines is the interoperability between python and SQL in Deepnote.
- Jobs on qualtrics drop the result of different surveys into internal SFTP, which is picked up by the data pipeline written in Deepnote to transform and write as tables within the redshift schema. This helps our team to measure the impact of any people program.
- LearnUpon [via API → data pipeline in DN]
- Application:
- Measure any learning and development program’s effectiveness. Dashboard for managers to evaluate completion rates for courses assigned to their directs in real-time.
- Application:
- Degreed [via FTP → data pipeline in DN]
- Degreed drops flat files into the FTP drive, which is picked up by the job running on deepnote to clean, parse and persist the data into redshift tables. We use the ELT approach for this.
Upleveling our infrastructure:
Recently, we have built cross-account connections between three AWS accounts to ingest the data from enterprise data warehouse and write into people data warehouse. We can leverage COPY and UNLOAD commands to optimize the performance of writing into S3 and Redshift cluster.
As Gusto continues to evolve and expand, the growth of our employee, candidate, and application data is inevitable. Constant enhancements to the scalability of our systems, data pipelines, and algorithms are necessary to build efficient tools that enable self-service access to this valuable data, while ensuring that data privacy remains a top priority as well as driving informed decision-making across the organization. Our People Insights infrastructure architecture excels in security-focused batch processing and scalability for integrating new data sources.

