That one time a memory leak almost took down one of our apps -- and how we fixed it

Like many web applications out there, Gusto uses asynchronous jobs to process various sets of information. Sidekiq is one such background processing library for Ruby, which we use at Gusto. Other such libraries include Resque, Beanstalkd, and delayed_jobs.
Recently, a series of design choices made over time led to the complete halt of all asynchronous jobs in one of our main applications. This was particularly disastrous because it happened overnight while running a lot of routine maintenence code. Our maintenance code handles some really important work: it ensures that people are paid accurately and receive the appropriate health insurance. When almost all of it was prevented from running, we had an incident on our hands. Here's how we mitigated the incident that night — and prevented it from ever happening again.
Uh-oh, there’s a problem
The next morning, I opened Slack to an innocuous message from a coworker: “Hey, do you know how to debug Sidekiq problems?”
“Sure I do,” I thought to myself, as I navigated over to our Sidekiq. Then, “uh oh.” I saw that we had hundreds of thousands of jobs enqueued, well over our usual number. We usually only had a few dozen running at a time, or maybe a few thousand if maintenance was running.
I checked out the currently running jobs: We had five workers running five processes/threads each, and all 25 processes were working on jobs of the same class. Let’s call that class DisasterJob.
At this point, some other early-risers were starting to notice that our app was having problems. Our customer support teams were wondering why certain key functionality wasn’t happening. Other engineers started posting about what they were seeing.
We first worried about our jobs backing up so far that they filled up Redis:
Then we wondered if the app code was surfacing any errors:
When the app code didn’t show errors, we checked our container logs:

Whoa—what? That last message made us realize what was happening. Instances of DisasterJob were hitting the memory limit on their worker container and taking the whole worker down with them, including the other four threads on the worker. And this was happening over and over again.
In software, we call this situation a “poison pill.” A poison pill usually means a job that you purposefully enqueue to stop a job runner that you don’t otherwise have the ability to stop. Unfortunately, this job class was repeatedly and un-purposefully doing that.
How we stopped the problem
Our first thought was to fix the out-of-memory problem was to increase memory allocation, but it takes a while to scale up new workers and we weren’t even sure how much more memory the jobs would need to run to completion. Deleting these bad jobs seemed like a faster option.
DisasterJob is a recurring job, so it was okay to delete enqueued jobs of that class since we could re-enqueue them later. So I tried deleting all of the enqueued DisasterJobs:
queue = Sidekiq::Queue.new("maintenance")
queue.each do |job|
job.delete if job.klass == 'Recurring::DisasterJob'
end
That made a big dent in our number of enqueued jobs overall, but it didn’t clear out the twenty-five jobs that were currently running, crashing, re-enqueuing, rerunning, re-crashing, etc. Jobs that are already running can’t be killed, so we needed to think of a different strategy.
“Why does this keep happening? Shouldn’t the jobs just die, take a worker with them, and then go be dead?” I asked.
It turns out that we were running an older version of a reliability strategy for Sidekiq, called Reliable Fetch. With Reliable Fetch, jobs on processes that die get sent to the “reliable queue.”
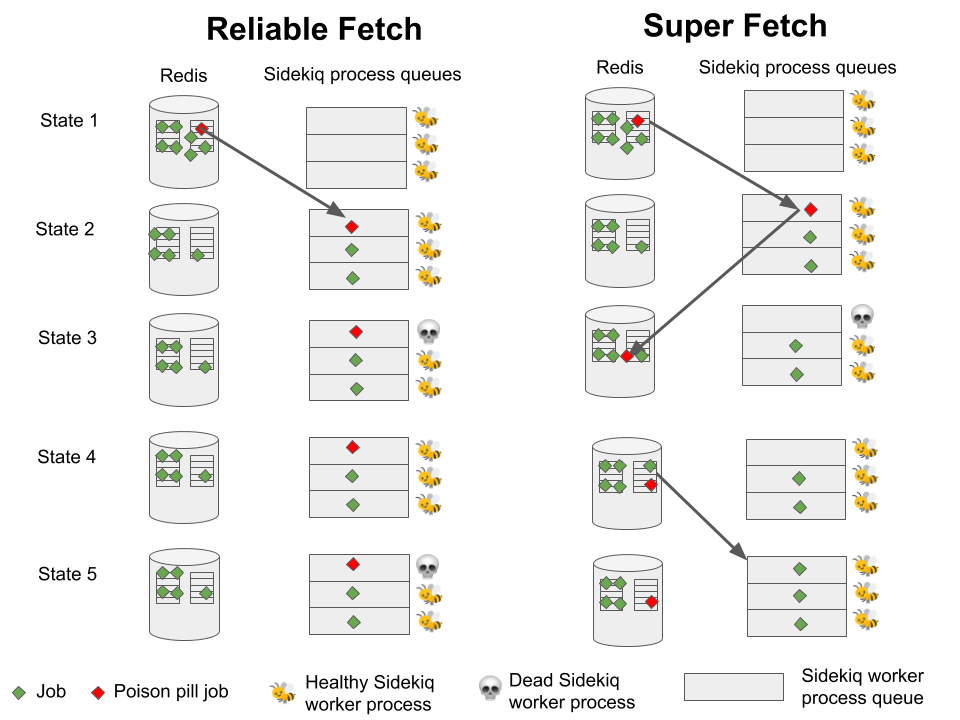
This diagram glosses over the storage details of reliable queue, but is a good comparison of the enqueuing and work strategies
When a new worker starts up, it pulls jobs from the reliable queue before pulling from the normal queues.
So jobs that took down their worker were the first to get enqueued to a new worker! And subsequently take that one down as well. These queues have the same name as their original queue, but with “_#{number}” appended. So, we tried clearing out those queues that we knew about, too:
# we ran this five times: maintenance_0 through 4
queue = Sidekiq::Queue.new("maintenance_4")
queue.each do |job|
job.delete if job.klass == 'Recurring::DisasterJob'
end
Still there were jobs being re-enqueued! This code snippet got us a list of all the queues, and we cleared out every single queue of that job.
all_keys = []
$redis.scan_each(match: '*') do |key|
all_keys << key
end
all_keys.select{|k| k.include?('queue')}.map{|k| [k, ($redis.llen(k) rescue "another data type for key")]}.sort_by{|arr| arr[1].to_i}
Phew! We finally had no more DisasterJobs running, and the rest of our enqueued jobs were starting to drain through.
Should we prevent this from happening again?
Before diving into prevention, first we need to ask: Should this be prevented?
I’m a fan of Cory Chamblin’s RubyConf talk, which suggests that we should only fix problems that cost more considering the probability of them occurring than the cost of their fix. Given that, this was a pretty catastrophic failure, and the cost to the business and the people we serve if maintenance is not run is high. We risk messing up someone's payroll or health insurance, and there’s no room for error when it comes to that type of work.
Although DisasterJob’s memory usage was the root cause of our problem, the real issue was that bad jobs would be immediately re-enqueued in a new worker after taking one down. This was due to the Reliable Queue reliability strategy. After a bit of research, we found that the creator and maintainer of Sidekiq recommends that users switch to a newer reliability strategy: Super Fetch.
Super Fetch cleans up jobs on processes that die into a private queue, and then pushes that private queue back into the regular queue. So instead of being immediately re-executed, bad jobs have to wait in line and let other jobs be executed first.
As an experiment, after updating to Super Fetch, we tried running all of the DisasterJobs again. They continued to take down their workers, but this time jobs of other classes were able to run too!
Of course, the enqueued jobs drained a little more slowly because the workers they were on occasionally fell victim to DisasterJob, but “things are running a little slowly right now” is much better than “nothing is running at all right now.”
Finally, we wanted to fix the root cause: DisasterJob. It was actually an old class, written three years ago and faithfully running successfully each night ever since. Why it suddenly became so problematic for us is also an interesting story, but we’ll save it for another blog post!
If you’re currently using Reliable Queues with your sidekiq, switch to Super Fetch. And consider playing around with the Sidekiq API—it’s very powerful!


