
Back in May 2022 the Gusto Payments Engineering team was staring at a graph. It was a rough estimate that showed that at the end of December 2022, we’d see our largest spike in payments volume ever thanks to a year of tremendous customer growth and various payroll schedules aligning to fall on the same date. The team was also staring at the logs of our payments packaging process which creates the files we need to send to the banks to make money movement happen. It showed us taking hours to package payments already. With some quick back of the envelope math, it was clear.
We wouldn’t be able to make it.
With the anticipated volume, we’d still be packaging payments by the time our banking partners stop accepting payments, and that’d leave our customers with unpaid paychecks. That simply couldn’t happen.
The Existing Process
It all starts with an ACH entry. Various processes in the system can create them via our Payments API, and each ACH entry represents money movement such as debiting an employer’s account, or crediting an employee. Entries are bundled together into an ach batch, and those batches are bundled together into an ACH file. That file is ultimately what we send to our banks to initiate money movement. This was the simplified process:

- Every 5 minutes check for unpackaged ACH entries
- Select up to 5000 at a time for each of our processing banks
- Using various criteria assign them to ACH batch sets, and assign those to new ACH files
The criteria determines what entries are appropriate to stick together in the same batch, and likewise what batches are appropriate to stick together in the same file. These include parameters like payment direction, processing bank, effective entry date, and more.
This process had several major drawbacks:
- To avoid race conditions that could result in doubling money movement, this process was single-threaded thereby significantly limiting our packaging throughput.
- The submission date of the ACH entry was not considered during selection for packaging. We could easily create an ACH file with just one entry weeks or months ahead of when we would submit to the bank.
- Since the process selected 5000 entries at random to then divide into batches we would often end up with some entries that do not belong together, resulting in ACH files being created with just a few entries each.
- If ACH entries were trickling in from various processes throughout the day we’d create ACH files with sometimes single digit entry counts.
- If an ACH entry is canceled then the ACH file it belongs to is destroyed, and all ACH entries associated with that file are reset to go back through the packaging process. This created a ton of file churn. There was a race condition here as well – if an entry was canceled but also happened to be going through packaging it could get un-canceled. Not good!
This process effectively worked out to a throughput of around 2,700 ACH entries packaged per minute. On a high volume day we could easily see 750,000+ ACH entries. At its worst our system spent upwards of 4 hours in a single day packaging nearly 500 files, and was still generating files by the time we started submitting to the banks.
While a large number of ACH files might not sound too bad, our partner banks have requested we rate limit uploads and wait 15 seconds between each file upload. Therefore tiny files with < 10 entries effectively take just as much time to submit as those with 5000 entries, and at best we can upload 240 files per hour. To help combat this an additional process ran 30 minutes before payment submission began to delete ACH files with less than 500 entries to force repackaging – further adding delays and file churn to the process and increasing risk.
Re-Architecting for Parallelism
Our biggest hurdle was the protection put in place to reduce race conditions which made this process effectively single threaded for each bank. This limitation meant we couldn’t just throw hardware at the problem, we needed to re-architect the entire process. The root of the race condition was the relatively naive picking of initial unpackaged ACH entries. If we created more threads they would pick up the same set of entries and potentially double package them.
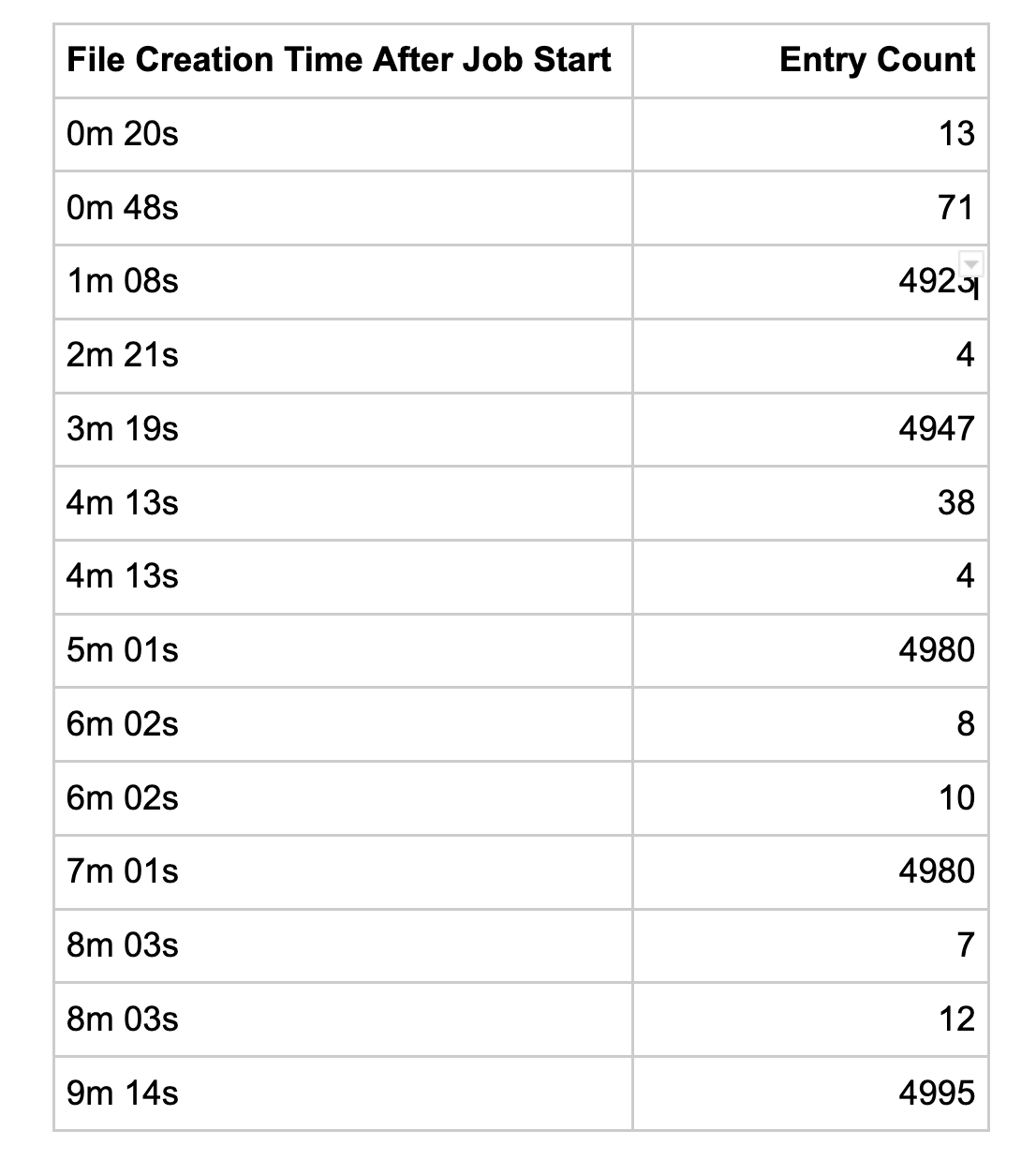
To safely address this problem we needed to assign ACH entries out to workers instead of letting them pick for themselves. We designed a new process following a map reduce architecture:
- Grab all unpackaged ACH entry ids, and initialize a new storage_key for Redis
- Distribute the ids to file grouper workers, each worker getting up to 1000 ids, along with the storage_key
- These workers fetch the full ACH entry objects and run them through a set of 17 different parameters to determine ACH batch and ACH file grouping parameters. These workers write back to Redis using the storage_key with the grouping parameters hashed together.
- Once all workers finish, the callback executes to read out the groups and divvy up the IDs accordingly so that no one file gets more than 5000 ACH entry ids, enqueuing a file creator worker for each set.
We deployed this new process next to the existing process with feature flags that controlled if the process was in a dry-run or live-run mode. We ran the new process in parallel for several days in dry-run mode which did everything short of actually creating files. The extensive logging allowed us to monitor performance and ensure optimal and correct grouping and proved very valuable.
Implementing the ACH Engine
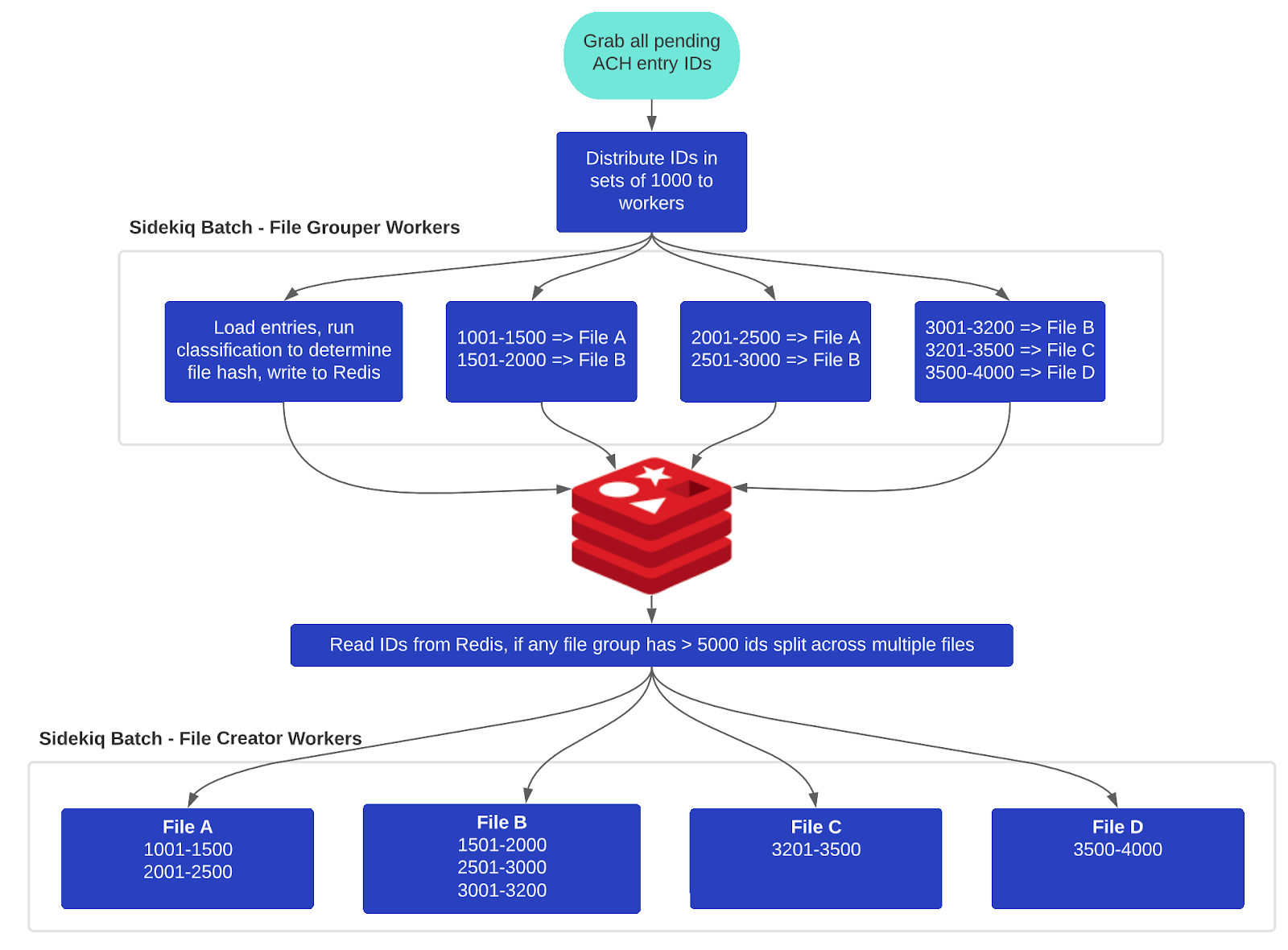
We’ve now got a process that can blast through processing, but it’s still triggered every 5 minutes and blindly selects all unpackaged ACH entry ids. Our system allows ACH entry objects to be created with submission dates in the future, sometimes days, or weeks ahead of when we need to send them to the bank. Additionally the two key types of ACH submissions Next Day and Same Day ACH (explained in a previous blog post) are sent to the bank a good 12+ hours apart from each other. It simply didn’t make sense to select all unpackaged entries as we’d end up generating small files that wouldn’t be submitted for quite some time. Here’s an example timeline:
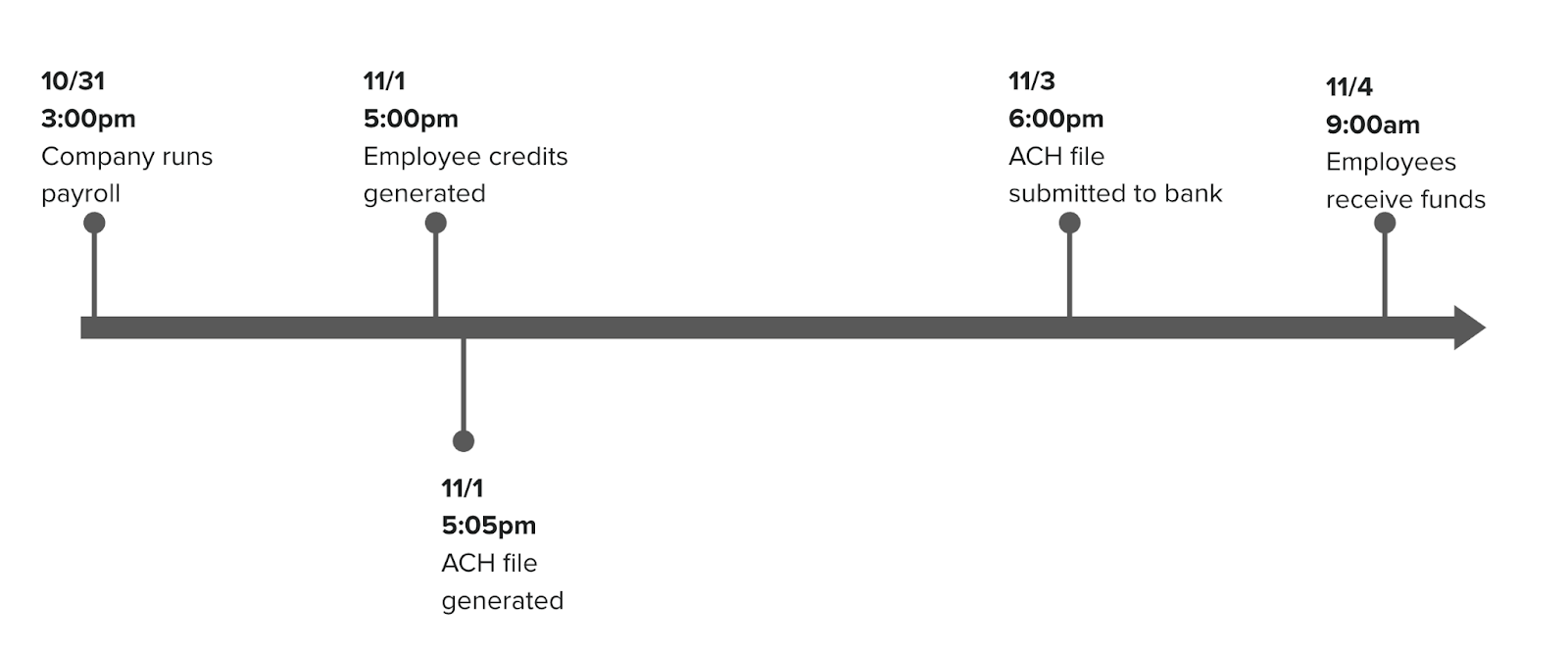
We also had a nest of interconnected jobs defined in our Sidekiq schedule that made it difficult to understand all the various submission schedules. This all started simply enough at Gusto with just one bank submission window in the evening, but as we grew we added a mid-day submission window. Then when we added same day ACH support, we added 3 more submission windows in the early morning. For each submission window we had to run related jobs as well. The schedule ended up with 19 entries with no clear relation between the jobs themselves.
As we were designing solutions we also realized that the schedule defined here aligned only with our primary banking partner. At the time we processed through four different banks, and it turns out they all had slightly different submission cut off times. By sticking to just one schedule we were leaving opportunities on the floor.
We dubbed our solution the “ACH Engine.” With it we’d create a rules based approach for configuring all of these interrelated jobs, and defining what types of ACH entries could be submitted for each window. The configuration looks a little like this. Each SubmissionConfig object defines default intervals between key events, optionally overridable where appropriate. Everything keys off of the two times submission_begin and submission_end, and the parameters like submittable_ach_type define what entries are eligible. This granularity allowed us a huge amount of control while remaining quite readable.

We implemented a job called the ACH Engine Runner that executes every 5 minutes and checks over the current configurations to figure out what jobs need to be done. It’s responsible for enqueuing up to six different jobs based on the current active submission windows and the step in each workflow.
This vastly simplified our Sidekiq schedule to just a single entry pointing to the new ACH engine runner. Beyond the organizational improvements, this new process made our packaging a lot smarter by allowing us to kick off packaging 2 hours before a given ACH entry needs to be submitted to the bank based on its submission_date parameter. This key change had several benefits:
- Our system now allowed payments to accrue throughout the day which helped efficiently max out our file limit of 5000 ACH entries per file
- Payments packaging is now much more focused since only payments that must be processed imminently are selected for packaging
- This more focused approach eliminates as much as 40% of the workload during critical packaging windows by smartly deferring it until it needs to be done
Now our timeline could look like this:
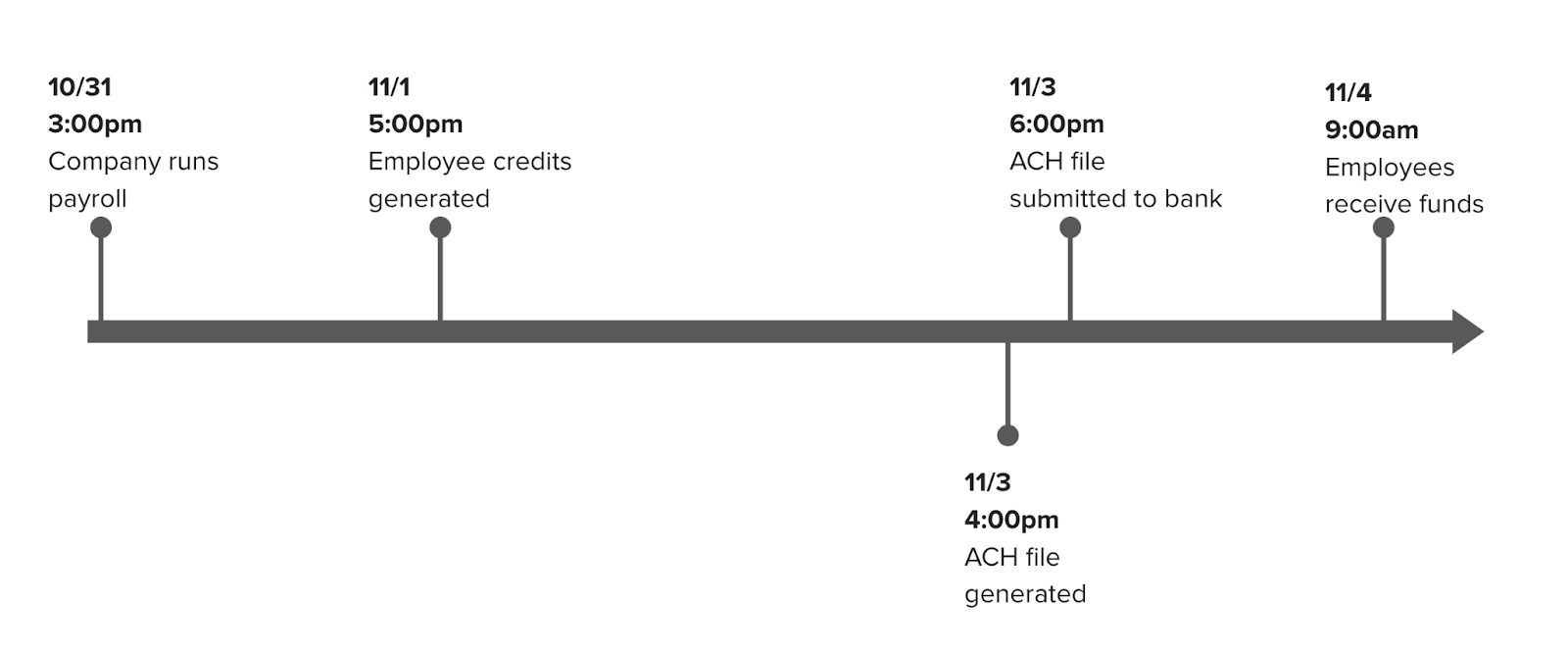
The end result of these two efforts is super efficient grouping of ACH entries into ACH files, and significantly increased throughput!
Solving the Redlock Bottleneck
Our packaging process is actually a series of asynchronous jobs and at the time we were dealing with a race condition that occurred when canceling an ACH entry. Basically if a job had started running and loaded these objects into memory and a parallel cancellation request could swoop in and modify the row on the database to mark it as canceled, the original job could overwrite this and un-cancel the ACH entry which is quite bad. Or even worse, if multiple processes picked up the same ACH entry it could end up being assigned to multiple ACH files and result in a duplicated payment!
To help combat that we utilized Redlock which is a Redis backed solution for locking entities. We’d lock up to 5000 ACH entries at the beginning of the process to ensure we got exclusive control, and if a cancellation request came along it’d have to wait for packaging to finish to process. This approach had some problems of its own which we’ll touch on later, for now we’ll focus on the performance. Our job runtimes were somewhat unpredictable and could spike as high as 7-8 minutes, and when we dug into the Datadog APM traces we discovered our locking solution was responsible for up to 67% of the runtime of a single job.

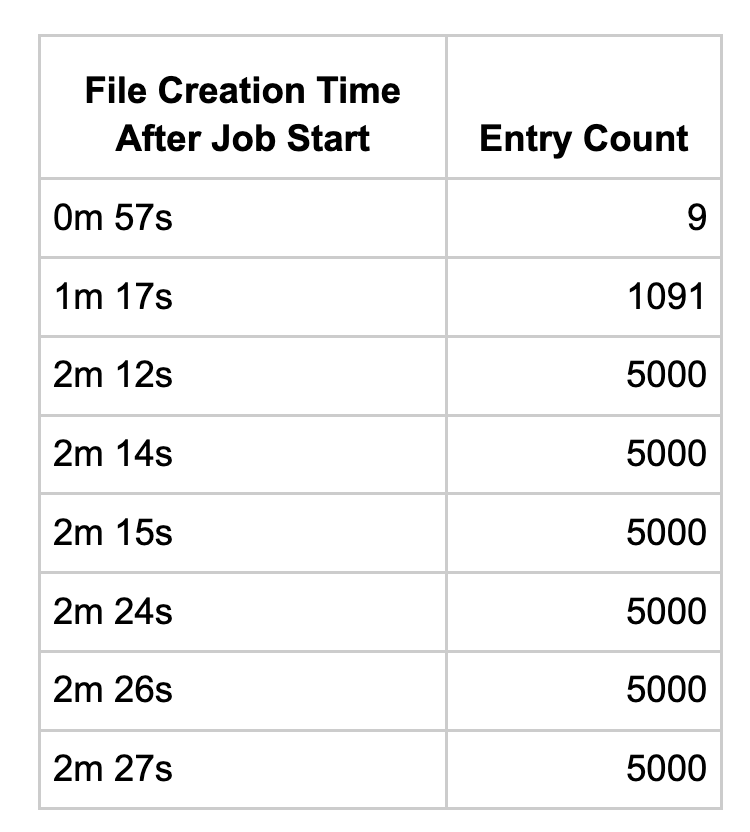
The problem got worse with increased parallelism as we were now pushing upwards of 300k to 400k IDs to Redis to lock. We initially tried some batch operations to reduce the number of round trips to Redis which cut round trips from 45k per job to just over 10k. Curiously though, this didn’t necessarily improve runtimes.
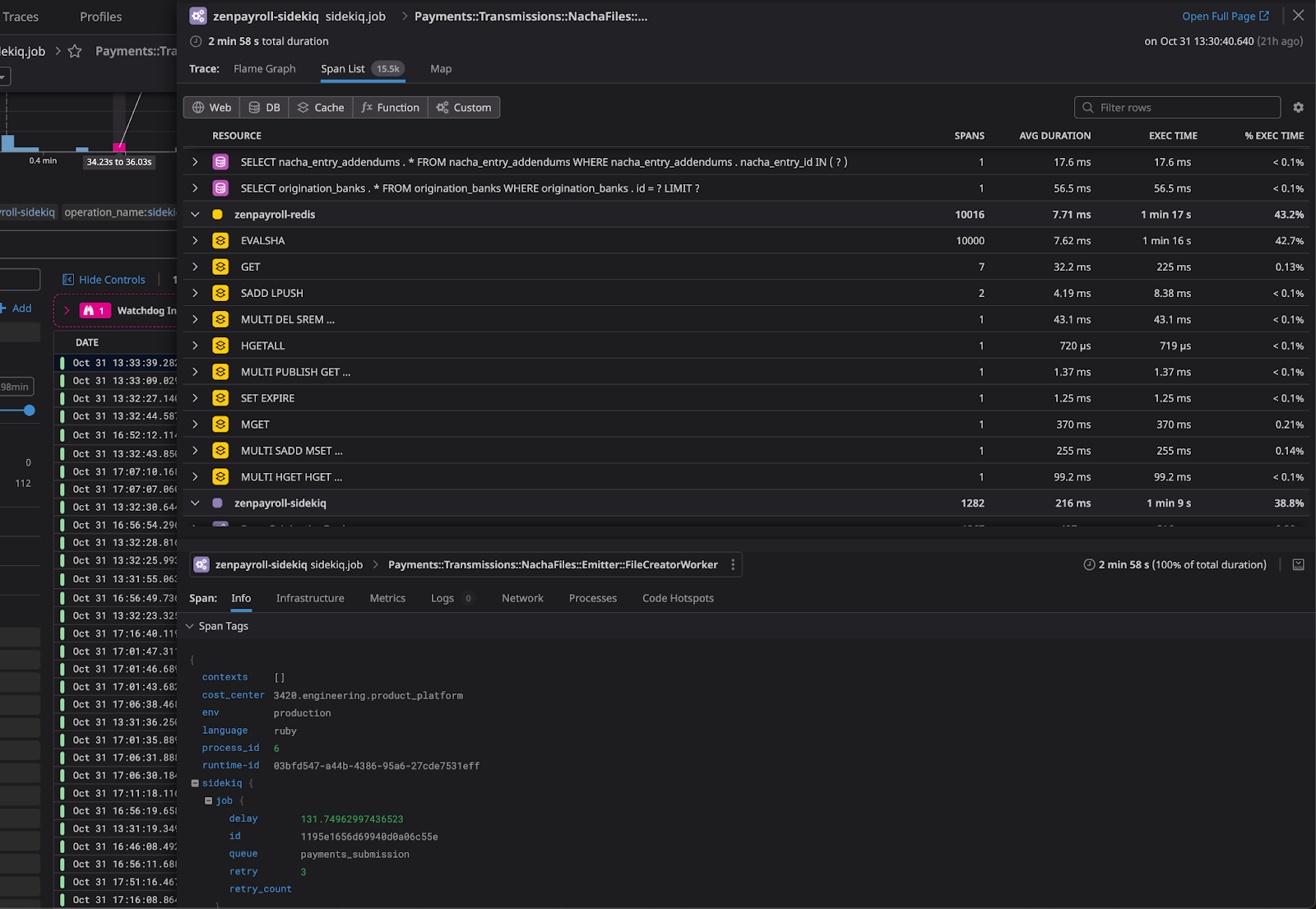
We decided to review what Redlock was actually doing, and found it stored a lot of metadata that wasn’t terribly useful. Ultimately we just needed to track the id of the ACH entry for all the currently processing entries. We decided to interact with Redis at a lower level by directly implementing set operations. The workflow became:
- Upload all IDs into a new set using SADD
- Fetch the names of existing sets from ach_entry_lock_sets
- Diff the new set from step 1 against those from step 2 using SDIFF
- If all members are returned no other process is using this set of IDs
- Add my the set name from step 1 to ach_entry_lock_sets
- Proceed with processing
- Unlock the set at the end with SREM and remove from ach_entry_lock_sets
The sets get a TTL set of 10 minutes so that if a connection or process is interrupted, Redis automatically unlocks them so we can gracefully proceed. The ach_entry_lock_sets has its TTL refreshed with each interaction as well.


The data structure in Redis as viewed in Redis Commander.
SDIFF proved to be the real key here as it’s capable of diffing hundreds of thousands of IDs in a split second. This new locking approach got our process to averaging just 1 second dealing with Redis.
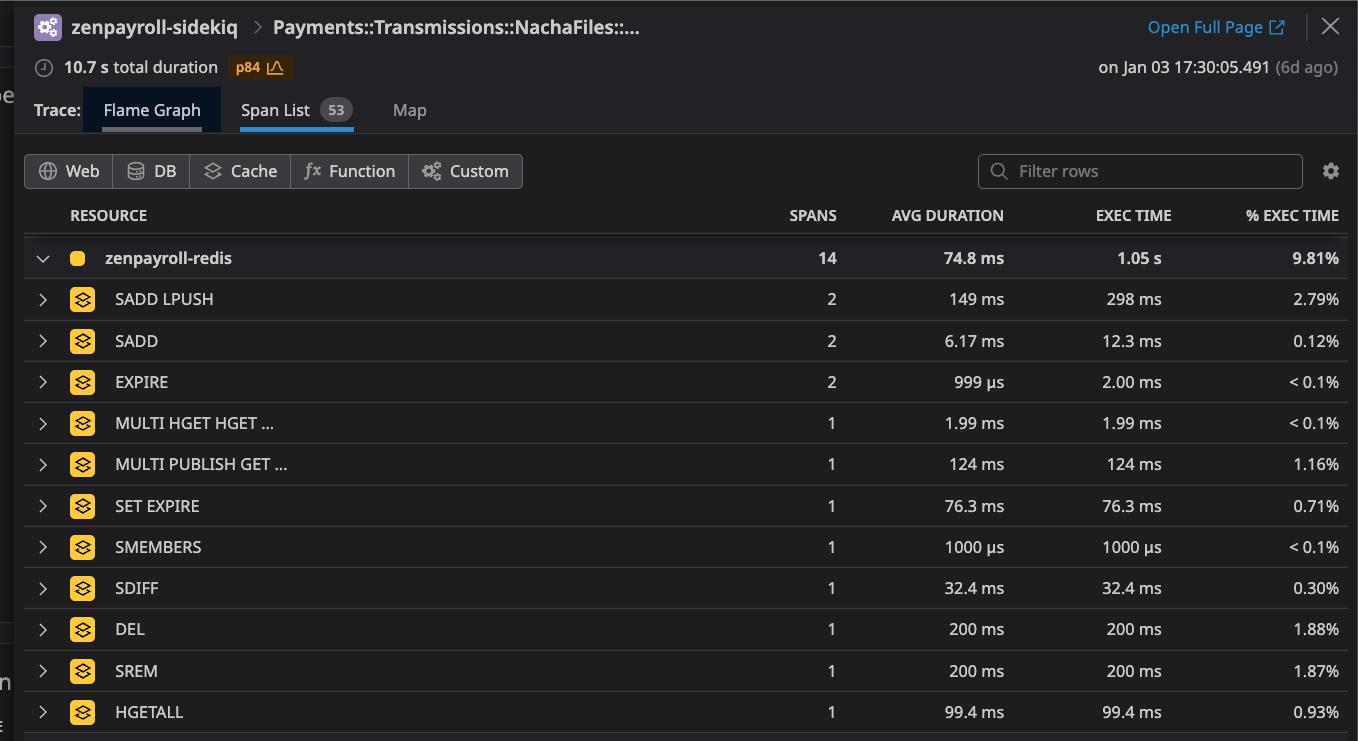
This improvement really took things to the next level in terms of performance.
Frictionless Cancellations
Cancellation of an ACH entry is a tricky problem when combined with concurrent packaging or submission processes. As mentioned above, this can result in un-canceling of an ACH entry if the packaging process overrides the cancellation process or we end up submitting an entry that is not supposed to be sent out. Our Redis based locking solution helped, but meant that we couldn’t honor a cancellation request if certain jobs were running on the specific ACH entry. That’s difficult to know when that’s happening and results in intermittent cancellations failing. Our requirement is that cancellation should always take priority, otherwise Gusto is at risk of potentially losing money, so we needed a better solution.
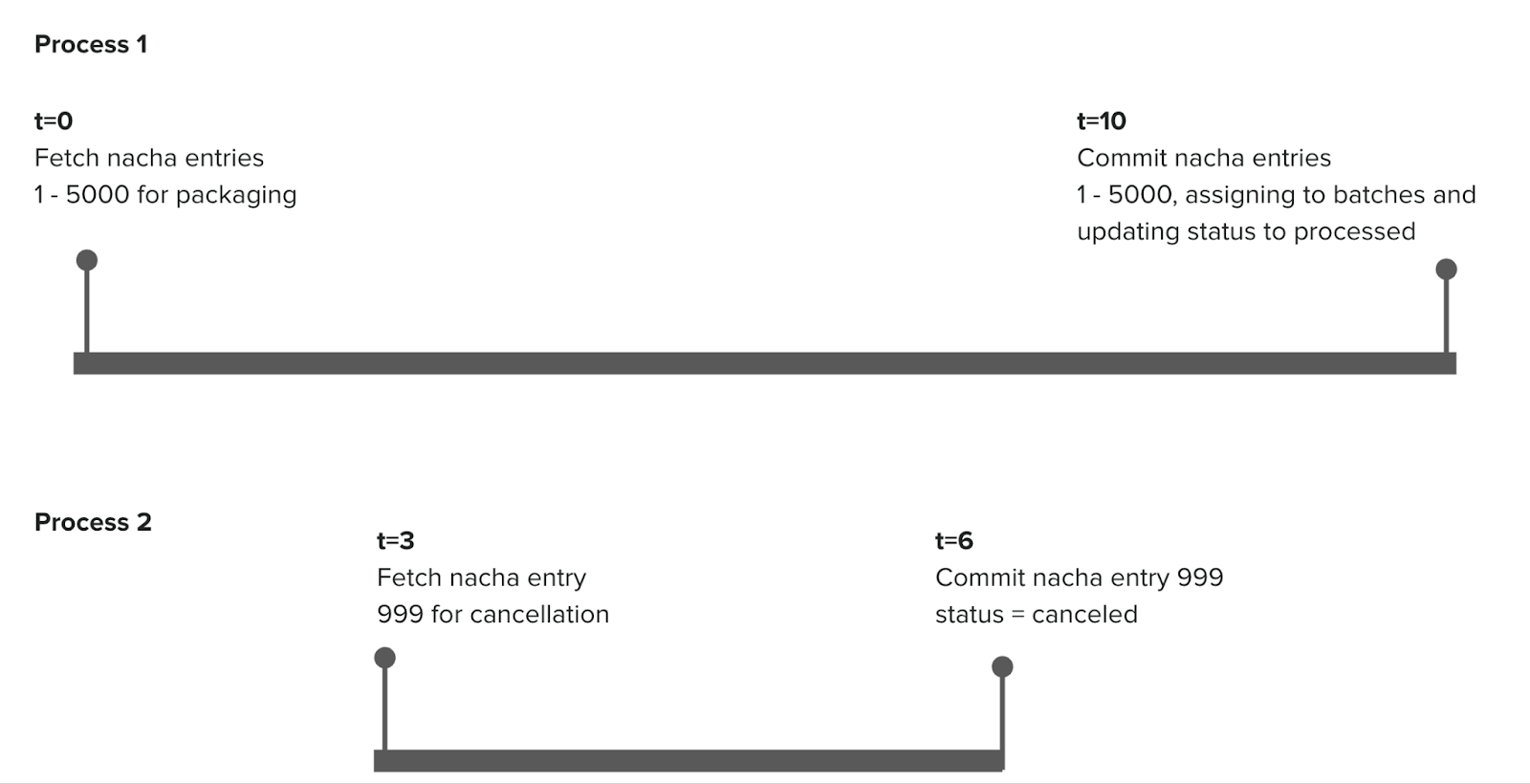
To handle race conditions between cancellation and packaging we implemented a new eventually-consistent approach wherein cancellations get persisted to the ACH entry cancellations table immediately, and asynchronously synchronized to the ACH entries table. If an ACH entry id exists in ACH entry cancellations this effectively overrides what the ACH entry’s state machine status says, and it now behaves as if the status was canceled. This table is always checked any time we build the ACH entry ActiveRecord representation, so even if synchronization hasn’t yet finished the ACH entry is effectively canceled. This system allows cancellations to be safely recorded without risk of other processes overwriting the status due to having an older representation of the object in memory. During file submission we check this status to ensure that no ACH entries in the file have been canceled, and then begin submission.
Another benefit of this new process is simplifying cut-off times for allowing cancellations. Previously our system cut off cancellation requests at 5:55 pm, since submissions started at 6:00 pm. Allowing a cancellation any later was deemed too risky due to how things worked and the possibility of race conditions occurring, or not honoring cancellations. However there were times where we needed to cancel something after this which required tricky workarounds involving multiple people – not good when you’re down to the wire and money’s on the line.
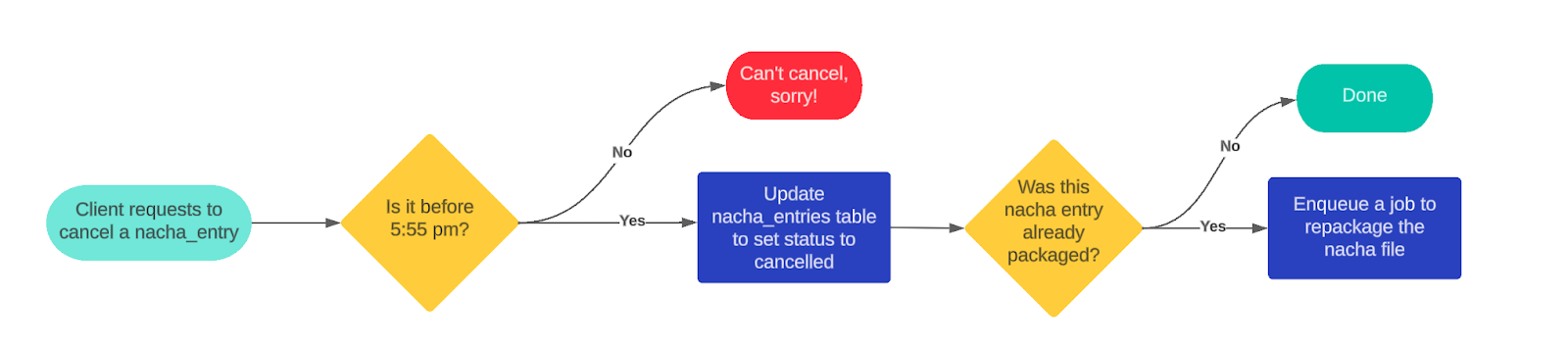
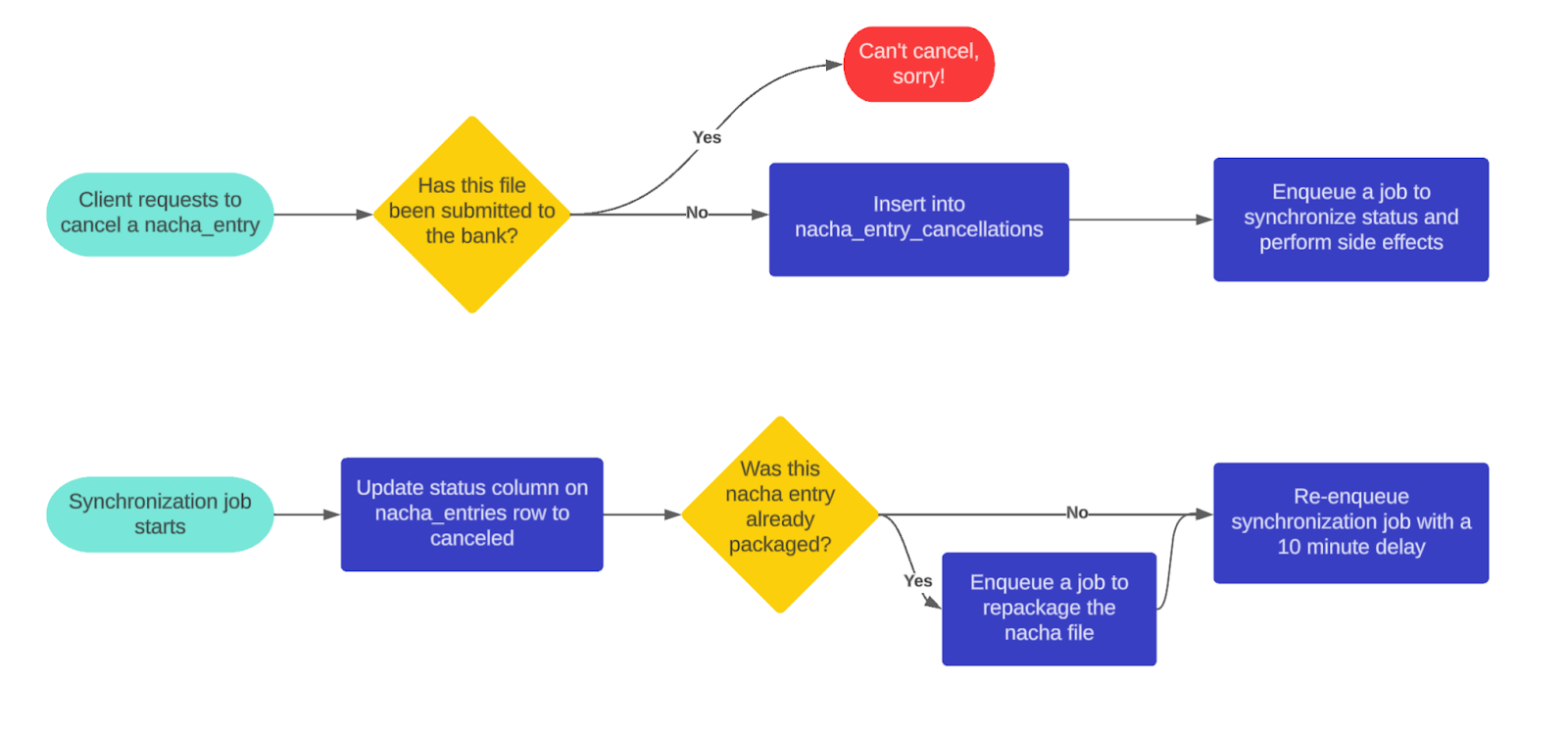
The new ACH entry cancellations process allows us to safely remove this time based cutoff, and instead rely solely on checking if a file has been submitted. As long as a file has not yet been submitted a cancellation request will go through and prevent submission. The synchronization job then takes care of cleaning things up like updating the ACH entry status accordingly and repackaging files. It also re-enqueues itself with a 10 minute delay after performing work to allow for any in progress work that might have overridden the ACH entry status to settle. This ensures we’ve recorded the cancellation correctly.
Upping our file limit
During high-volume days the re-architected process created quite a few files with 5000 entries, sometimes in excess of 250 files. This pattern is atypical for ACH files which allow up to 1 million entries, and $99 billion in transfers. Organizations typically transfer just a few large files a day as opposed to hundreds of smaller files, and interestingly this created some problems with one of our partner banks with their acknowledgment file generation process.
Acknowledgment is a process where banks will perform high-level checks for each ACH file received and confirm whether it looks good or not. They’ll generate an acknowledgment file for use in automated processes, as well as send an email confirmation. On higher volume days our auto acknowledgement system that fetched these files would routinely miss around 10 to 20%. This required our payment operations team to manually acknowledge some files by searching through emails and matching them to ACH files via our internal web application. This was a lot of toil on top of their regular work that was still required.
We met with our banking partner and their recommendation was to throttle file uploads and wait 15 seconds between uploading. This would limit us to 4 files per minute, or 240 files per hour assuming best case file transfers and no overhead. To safely make this change we’d have to increase our entry count limit per file, but that would directly increase job runtimes for generating files which scale linearly with entry count. We needed to pull out some deep optimizations to keep runtimes in check. Our target was to stick to under 1 minute of processing, and we were already close with ~5000 entries per file.
We investigated and determined that our process where we generate static fixed-width files following ACH specifications is the bottleneck. Internally, we refer to it as ContentGenerationWorker. We leveraged Datadog’s APM traces with additional instrumentation to designate spans to help determine where exactly the slowness in the worker is coming from and found three root causes.
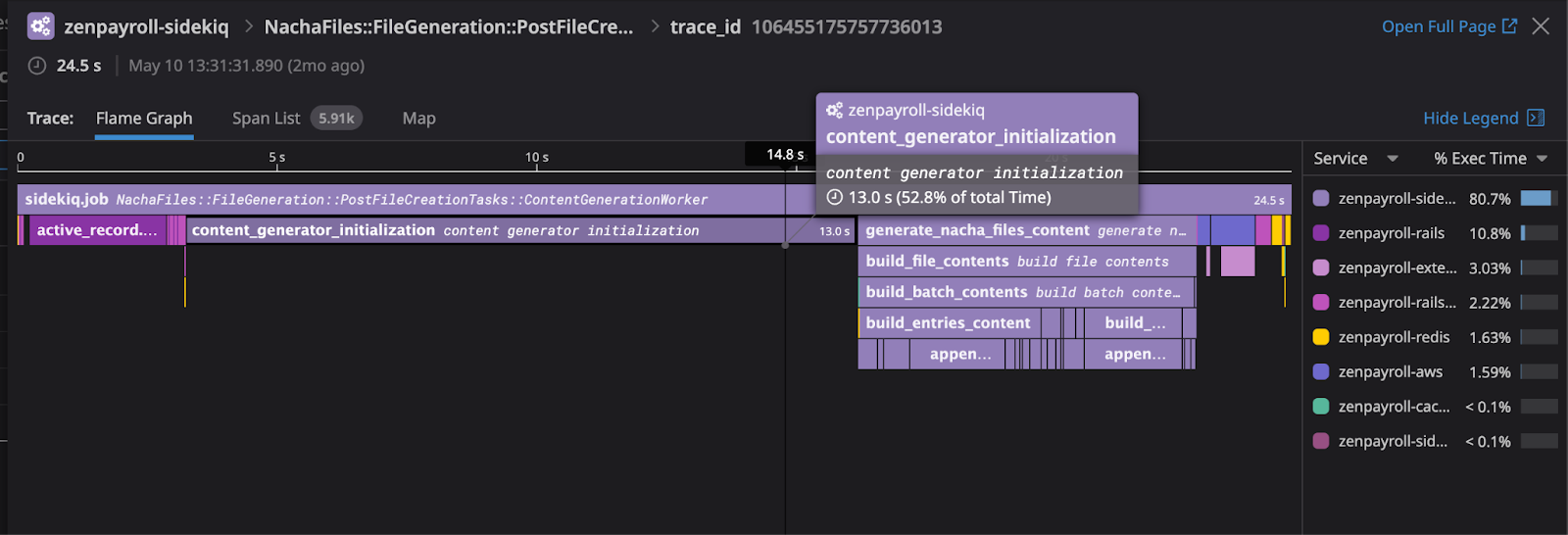
#1 – We found initialization was taking up more than half the run time. It turns out we were performing unnecessary checks to validate that the required fields were not null. This was a recursive check - an ACH file can have multiple ACH batches and each ACH batch can have multiple ACH entries. This relied heavily on meta-programming and checked 9 fields per ACH entry resulting in over 45,000 send calls to the Ruby objects for an ACH file with 5000 ACH entries.
All of these checks were redundant as we already had database or code constraints that didn't allow null values in the first place. We just removed this check. On to the next issue!
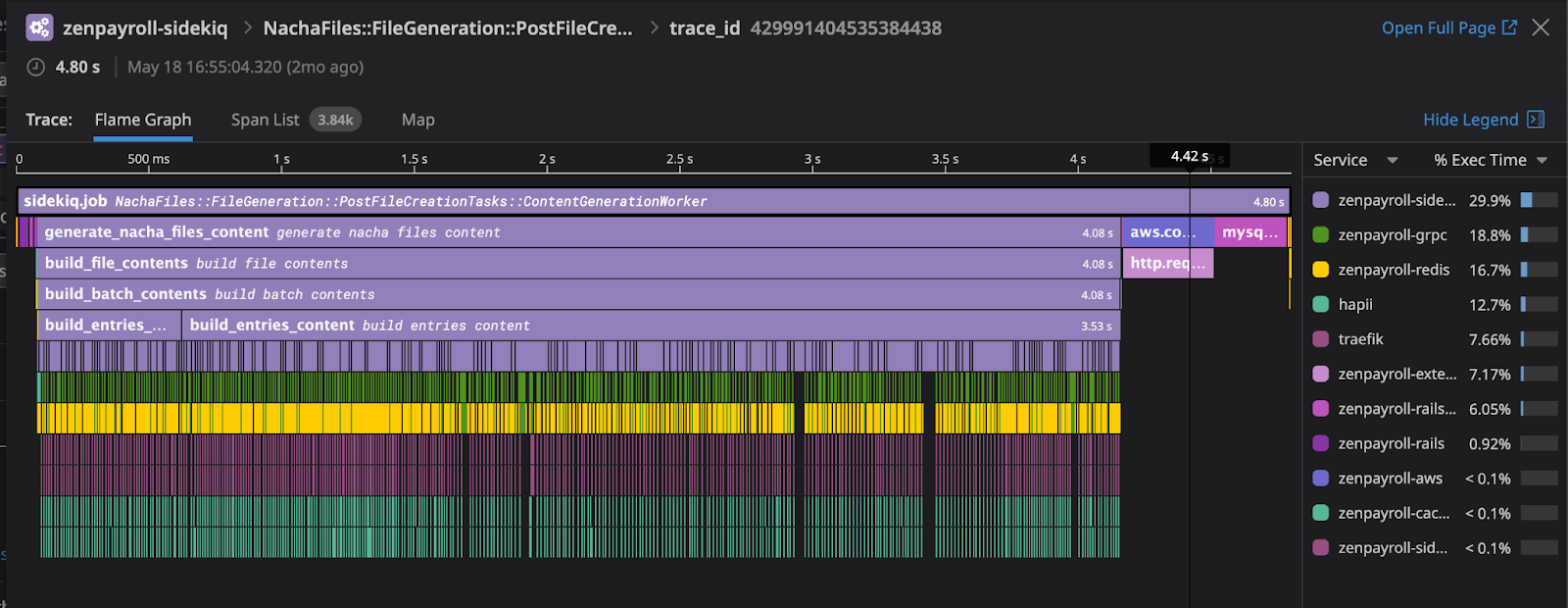
#2 – Sometimes ACH entries can have addendums. These addendums contain sensitive data and are stored in HAPII - our internal data store responsible for storing sensitive data. We found what basically amounted to n+1 queries, only to an external system. We’d sometimes make up to 5000 calls if the ACH entries involved had addendums. We implemented a mechanism to leverage the bulk read API provided by HAPII and memoize the result, vastly improving things.
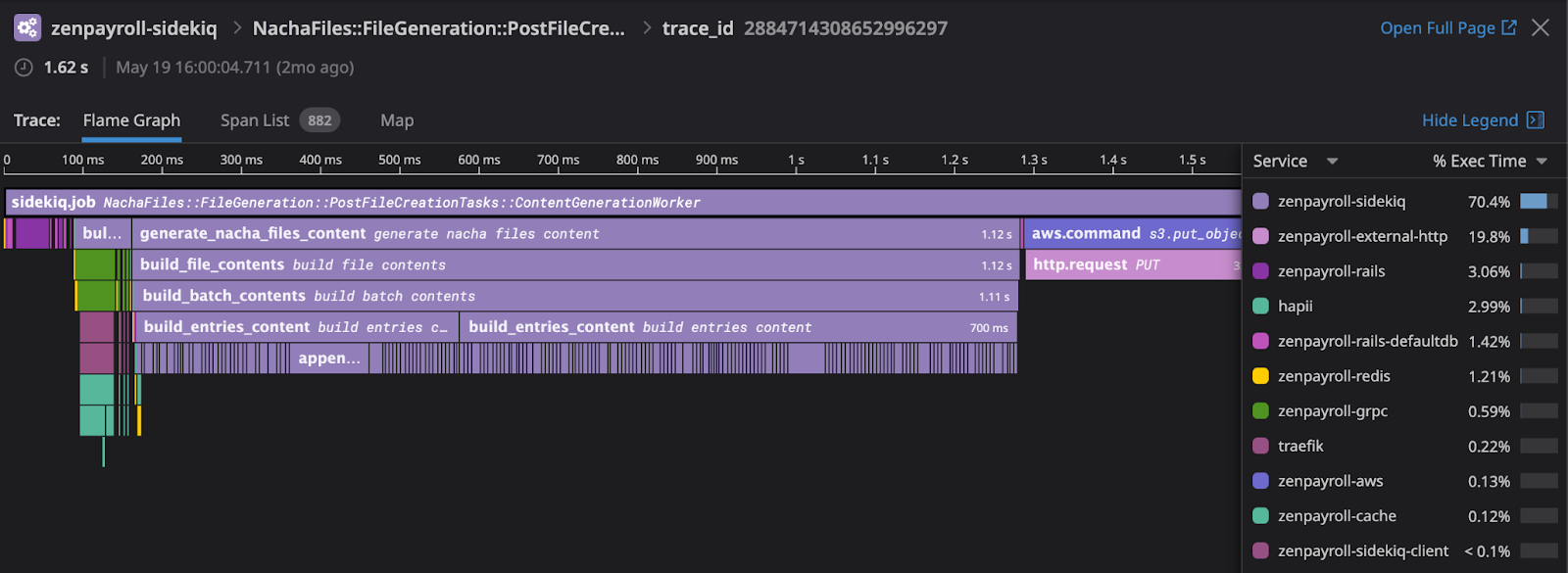
#3 – Finally with us now confident that our build_file_contents section of code had no external service calls, we dug into why a section of code that runs purely in Ruby and just writes a text file with just over 5000 lines could take over 1 second on a modern system. We found that our library frequently used += for string building instead of << to append to the same object. We use Fixy and while this change had already been implemented in the published library, this was a gem that started at Gusto and we had an early version in our codebase. Since ACH files are 10-15 fields per row, this ends up being a significant number of string objects that Ruby has to churn through.
plus_equals = ''
append = ''
Benchmark.bmbm do |p|
p.report('plus_equals') { 10000.times { plus_equals += 'foo' } }
p.report('append') { 10000.times { append << 'foo' } }
end
Rehearsal -----------------------------------------------
plus_equals 0.055955 0.089045 0.145000 ( 0.145253)
append 0.000412 0.000036 0.000448 ( 0.000449)
-------------------------------------- total: 0.145448sec
user system total real
plus_equals 0.103716 0.029622 0.133338 ( 0.133311)
append 0.000416 0.000005 0.000421 ( 0.000419)
Comparison of += to << – Using append is over 300x faster
With all of these changes queued up, we finally felt confident to start incrementing the file count. We leveraged the ACH Engine rules system to selectively increase file count limits per window, starting with the early same day ACH windows. If a problem did arise because of the increased limit, having it occur early in the day would give our engineers time to debug and resolve issues before it had an impact on customers. We slowly ramped up to 7500 entries, then a few days later to 10,000, then 15,000, 20,000, and finally landed on 25,000. We’d monitor for performance and potential issues along the way, and we’re super pleased with the results.
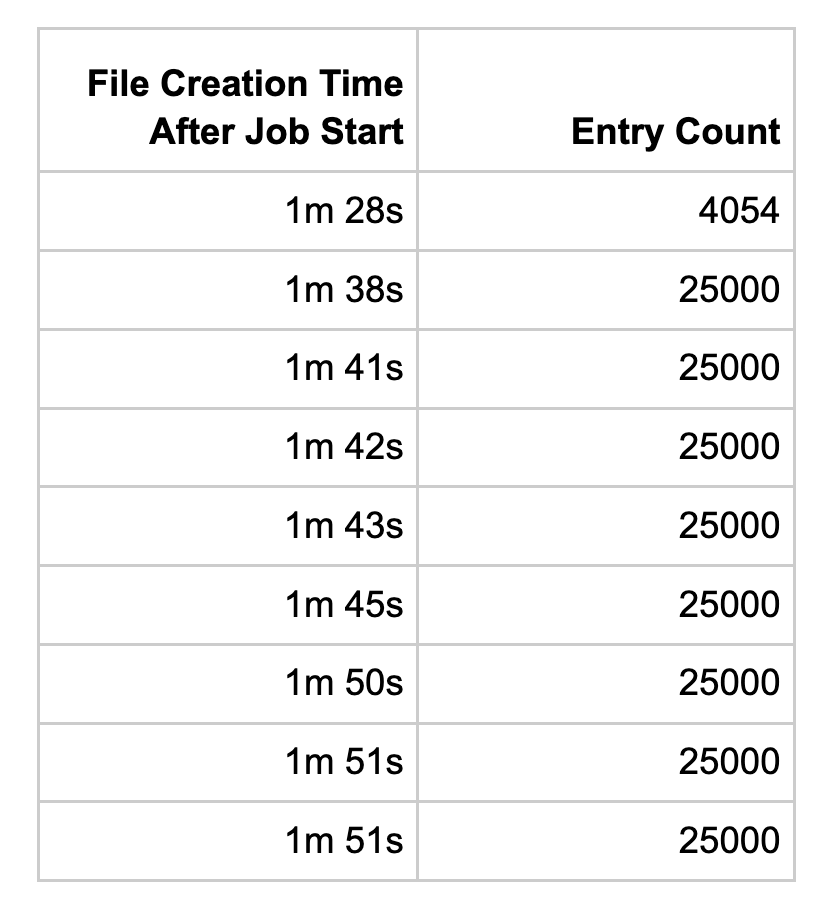
The final performance figures for this effort after nearly a year to date of effort:
This re-architecture has taken Gusto from being on the verge of being unable to process payments on time to giving us years of breathing room. Many thanks to our teammates Melissa Bromley and Elliot Butterworth for helping us with this journey to scale our ACH process.


