Active Record validations are an integral part of any Rails application, and with good reason. Maintaining a comprehensive set of validations guarantees that only valid and consistent data will be written to your database.
That’s great, but what about data that is already in your database? While validations ensure that your data is valid when written, they do not guarantee that it will stay that way. So how often does valid data suddenly become invalid? More often than you may think. Here are just a few examples of how it can happen:
- You or another developer on your team adds new validations but forgets to properly migrate existing data.
- Your application updates records using methods that skip validations (e.g. update_attribute, update_column, or save with :validate => false).
- You use uniqueness validations and have multiple app processes running. Two processes try to insert a record at the same time, the uniqueness validation passes in the both processes, and you end up inserting two records instead of one.
So you might have some invalid data, so what? Why should you care? Here are two reasons:
1. Having a single failing validation will block the whole record from being updated. This means your users may see errors for fields they aren’t even editing. This can be even more confusing if the field failing validation is an internal field and isn’t even on the form.
{<1>}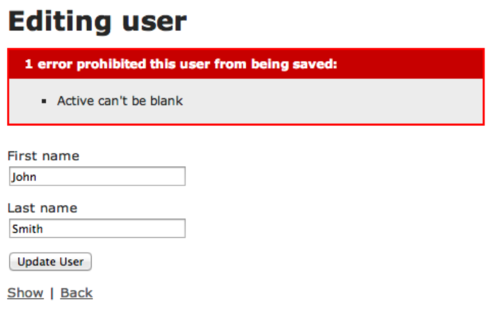
Fig. 1 - How to frustrate your users
2. Validations are like assertions; they represent assumptions that your application is making about the underlying data. Having invalid data means those assumptions are no longer true which means your code may start behaving unexpectedly.
One of the greatest benefits we’ve found in keeping our data clean is that it helps unroot bugs that we otherwise might not have seen. When we find a validation error and start digging into it we often end up finding a significant bug in the code caused by some obscure, yet valid user edge-case.
Our Solution - Introducing BrokenRecord
Ok, so you’re convinced that keeping your data valid is important. Here’s what we do at Gusto to make sure our data stays valid, and it has helped us time and time again to catch bugs before our customers do.
The principle is very simple: run validations on all records in an automated job and alert the dev team when something fails. There were a few design requirements however:
- The job should run on production data, but should not run on production servers. We didn’t want to tie up our production CPU’s or worse, potentially alter the data as a side effect of a validation or callback.
- While the job should use production data, it should use the source code from our dev branch. This helps us catch bugs before they’re deployed.
- Triggering the job on code changes is not good enough since data can become invalid without any code changes. Therefore, we scheduled the job to run every three hours.
- We needed to skip some specific validations. For example, we have some validations that lock a record from being updated. Calling valid? on one of these records would return false even though the committed data is consistent.
- We wanted to skip some models entirely. For example, models that were introduced by third-party gems such as paper_trail.
- We wanted the job to run quickly, so we leveraged the parallel gem to run validations in parallel.
We addressed the first three requirements by setting up a scheduled job on Leeroy (our Jenkins CI server). To satisfy the last three requirements we built a simple rake task and we’ve been running it internally for several months.
Running validations periodically has been so helpful to us that we’ve decided to open-source it.We packaged the rake task into a gem and named it BrokenRecord. The source code is available on GitHub.
To use BrokenRecord, simply add this to your Gemfile and run bundle install:
gem 'broken_record'
You can use BrokenRecord to scan all the records for all models in your application, or you can scan specific models:
# Scan all records for all models in your application
rake broken_record:scan
# Scan all records of the User model
rake broken_record:scan[User]
BrokenRecord can also be configured to always skip some models and to run a given block of code before each scan. We configure BrokenRecord in an initializer. Here’s an example:
if defined?(BrokenRecord)
BrokenRecord.configure do |config|
# Skip the Foo and Bar models when scanning.
config.classes_to_skip = [Foo, Bar]
# BrokenRecord will call the block provided in before_scan before
# scanning your records. This is useful for skipping validations
# you want to ignore.
config.before_scan do
User.skip_callback :validate, :before, :user_must_be_active
end
end
end
There’s a traditional way of looking for bugs by starting out stepping through code in your head in much the same way a computer does. Then there’s this other way where you start out looking for inconsistencies in your data. It’s sort of like looking at bug finding from a bottoms up approach (data to code) instead of a top down (code to data).
"Hygiene is important. That’s one of my failings. So I’m always being called on that."
-Dan Aykroyd
Keeping our data clean has been tremendously helpful to Gusto, so we hope you’ll find this gem useful too. Your data may be a diamond in the rough right now, but treasure it, polish it carefully, and it’ll shine!