Accelerating Operations Through Automated Data Loading and Population with Optical Character Recognition (OCR)

Traditionally, R&D Tax Credits has been operationally intensive. Gusto leads the way in simplifying access to these credits for small and medium-sized businesses (SMBs) through automated, self-service solutions. To ensure compliance with IRS standards, we request relevant documentation from our customers, including business owners and accountants, regarding their business operations.
Problem: The human cost
For our Operations team, extracting and populating crucial data from provided documents demands a substantial amount of time when serving our customers.
This includes information such as income, job titles, work locations, dollar amounts, and related details. The top three document types most commonly encountered in this process are tax returns (e.g., Form-6765), W-2 forms, and documents related to gross receipts. These documents are delivered in formats that range from form-like pdf files to images taken with a phone camera. Each contributes to the intricate task of data extraction and processing.
To set a baseline view of how time consuming this problem can be, let’s take an example:
Let’s say a company that has been operating for the past 4 years has 20 employees. The company has a tax return per year for a total of four tax returns. Each of the twenty employees also has one W-2 form per year. This results in 84 total documents because of the following math:
Total documents = 4*(1 + 20) = 84.
Internally, we have estimated time consumed in manually loading this document data into our system to be ~60 mins for a customer similar to the example. The total time to serve customers also increases proportionally as we scale in customers. This process is prone to human error because it is manual and our Operations team may be serving multiple customers at once.
At Gusto, we strive to serve our customers efficiently and maintain a high bar for accuracy. Automating this process helps us do both. We have identified immense value in using Optical Character Recognition (OCR) to serve our needs.
Implementation & Architecture
OCR technology can parse images and documents with structured or unstructured data, extract information from it and export the data into a custom form of your choice. Gusto uses one such OCR service from Instabase. Behind the scenes, it's a ML model that is trained on a set of documents of the same format as the documents to be processed.
The implementation supports two main processes:
- Initiate OCR job for a document
- Human review of OCR results
Initiate OCR Job
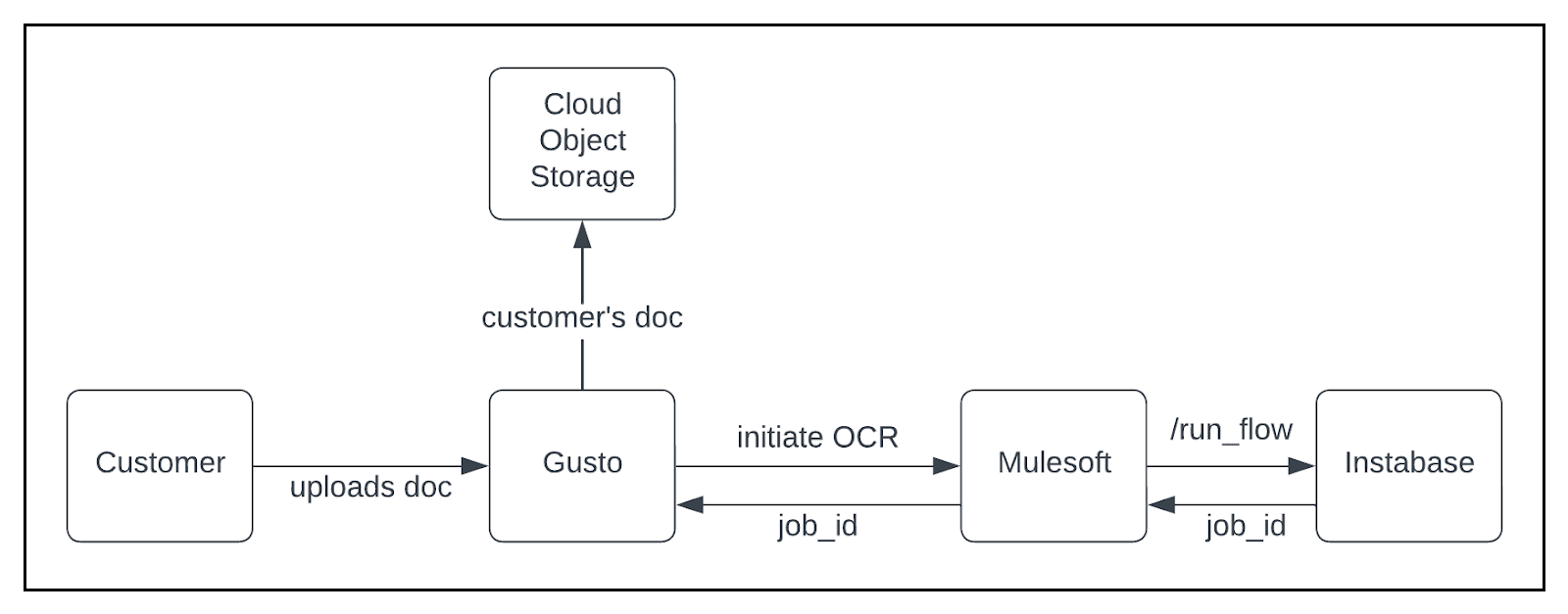
Upon a customer uploading a document, we initiate an OCR job using Instabase. This process is facilitated through Mulesoft, which functions as our orchestration layer for polling job results and sending them to Gusto. We retain the job_id provided by Instabase as a reference to associate OCR results given the asynchronous nature of the process.
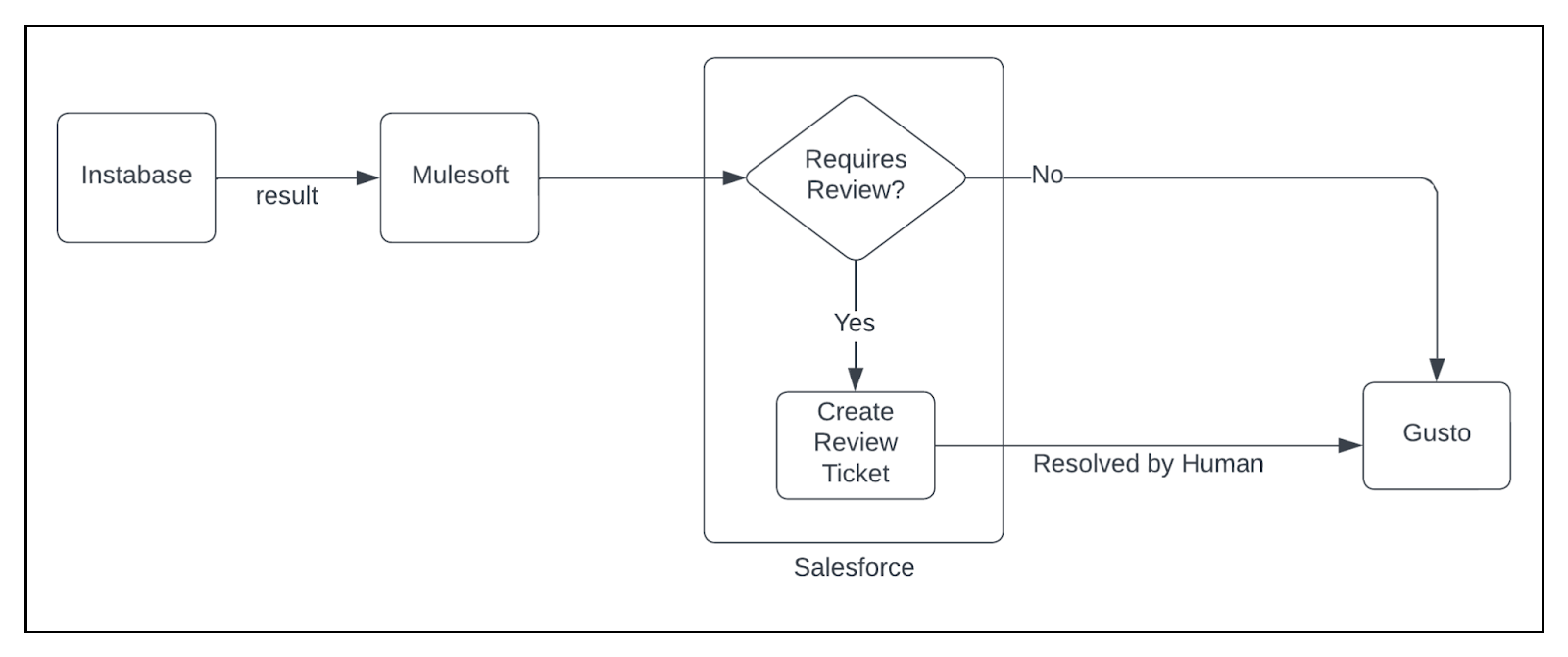
Human Review
Instabase publishes OCR results for a document which contain data extraction scores for each extracted field. These scores indicate likelihood of correctness of the extracted data. If the scores for all the fields of a document are above a preset threshold, the data is pushed to our application from Salesforce via an integration. In the case of below threshold confidence for any field, we create a Salesforce ticket for Ops team to review the under-confident fields. Once the fields are updated, the data is pushed to our application and the ticket is closed. This also serves as an input to the OCR ML model to improve its performance, as the incorrectly extracted data is annotated with correct values. Annotation from human review is an integral component of Human-In-The-Loop Machine Learning.
Data Security
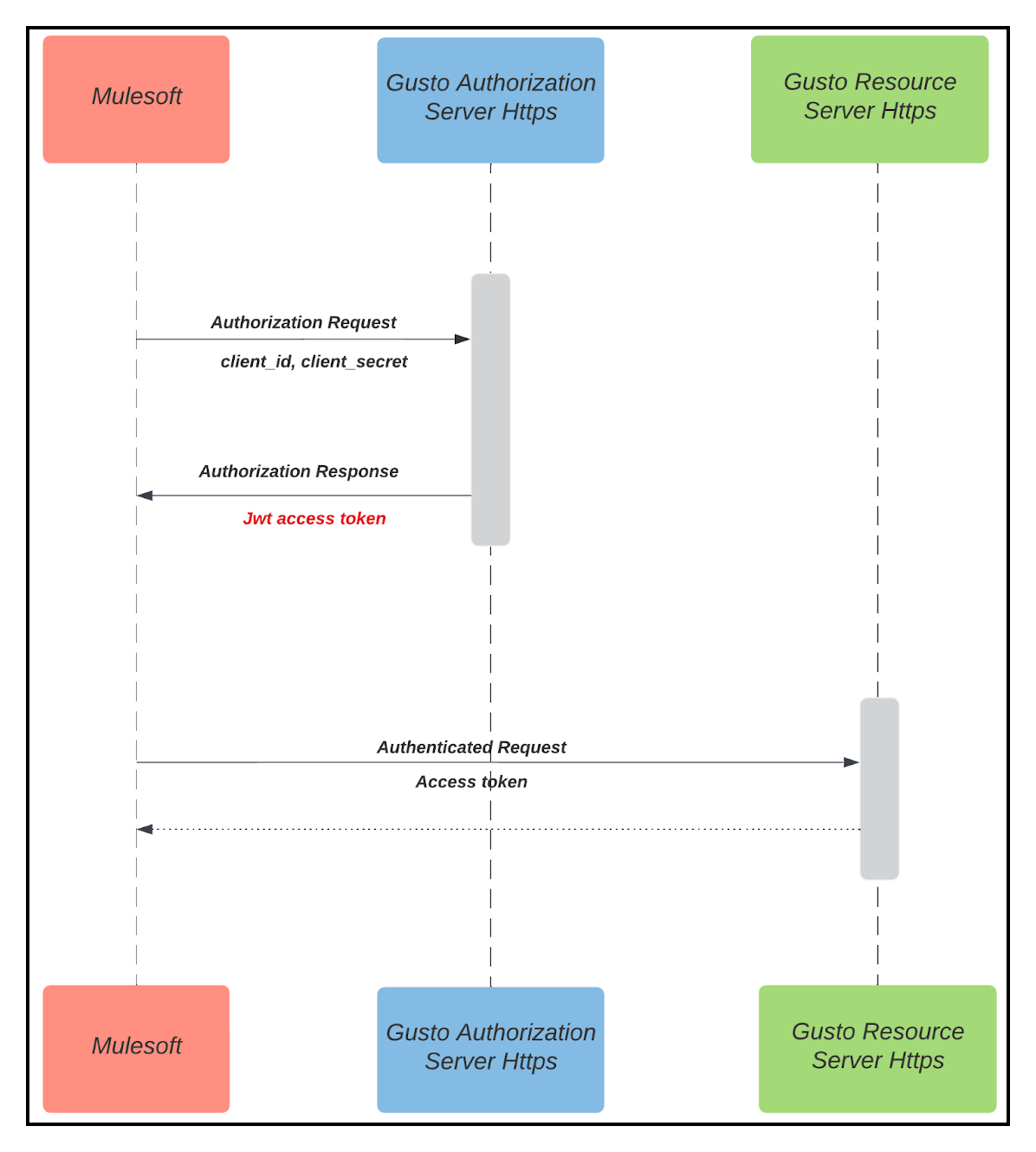
As we transmit the documents to Instabase for OCR (Optical Character Recognition) processing, we have implemented robust data security measures.
While our Instabase instance resides within Gusto, we take additional steps to safeguard the data transmitted over the network. All data packets are encrypted to prevent unauthorized access during transmission. Additionally, the communication channels between Gusto and Mulesoft APIs are secured using OAuth 2.0 authorization, adding an extra layer of protection to the data exchange process.
Specifically, in the interaction between Mulesoft and Gusto APIs for the POST OCR results, we employ JwtToken for simplified token management. This ensures secure and authenticated communication between the two systems, enhancing the overall data security posture.
Closing the Loop
With this system, we are seeing a dramatic increase in efficiency of our Operations team in serving our customers. Estimating the time saved on the same example customer at the top:
- Document count: 84
- Document count requiring human review: 2
- Time spent on 1 human review for OCR low confidence: ~3 mins
- Total human time spent on this customer: 2*3mins = 6 mins
Compared with initial estimate of ~60 minutes for our example customer, we have reduced the time spent by our Operations team to just 6 minutes for a total time savings of 54 minutes 🎊.
Challenges and Next Steps
With the work done so far, we have established a base of using a ML model to extract data from documents and use it in our business process and operations.
Our immediate next step is to utilize the human-review annotations as input to improve the ML model in an Online Learning setting. A common concern in doing this is adversarial inputs to the model during the human review, however we sidestep this problem by the virtue of being internal Ops facing and hence not dealing with bad actors.
The biggest outcome of Online Learning will be the creation of a self-sustaining environment wherein existing as well as new models can continue to improve with little or no intervention, besides the natural value of further decrease in manual Ops time spent on manual work.
Special recognition goes out to Melody Yeung, Richard Nienaber, and numerous others who have played integral roles in making this work possible.
