
In part 1, we covered the goals and benefits of isolating the most sensitive customer data to a separate service, that we call HAPII - The Hardened PII store. Briefly, the isolation of the data, explicit retrieval API, and greater observability into how data is used have helped drive change in data handling and exposure practices. In this part, we will discuss the architecture and implementation details of HAPII that provide for secure and efficient access to sensitive data.
The service interface
HAPII provides a gRPC-based contract for storing, retrieving, and searching data. We selected gRPC for the following reasons:
- The client and server implementations are high quality, and available for a wide variety of languages. While Gusto primarily uses Ruby, some teams are starting to adopt Go and Kotlin. All three are well supported by official gRPC implementations that are widely used in production.
- The gRPC protocol and the protocol buffers message format are wire efficient, and also often cheaper to encode and decode than JSON. Smaller messages and less encoding overhead help reduce request processing latency.
- As gRPC is built on top of HTTP/2, multiple requests can be multiplexed onto a single connection in a way that avoids head-of-line blocking. This further supports latency reduction at the 99th percentile and beyond, particularly during bursts in request traffic.
These benefits can be realized in a more conventional REST-like API, when care and attention are paid to the implementation, however gRPC brings it all together by default.
HAPII offers six RPCs for objects: read, batch read, write, search, find equivalent, and delete. Batch read, find equivalent, and search offer paginated responses in the style recommended in Google’s API design guidelines.
One may wonder, given gRPC’s ability to support concurrent requests on a single connection, why a batch read operation is necessary. We found that, as Ruby is effectively single threaded and synchronous, it was not efficient to fetch even moderately sized sets of data using individual read requests. In production, we frequently see batch reads related to payroll operations fetching hundreds of values at a time. The additional latency incurred through multiple sequential requests can be easily mitigated with a batch read operation.
This is less of a problem in other languages that support asynchronous processing, such as in Go or node. Ruby 3.x has better support for asynchronous processing, with the introduction of the Fiber Scheduler. However, the overhead of individual requests relative to the size of the data retrieved can still mean that a batch retrieval operation is justified. Until fibers become a much more established tool for Ruby developers, paginated batch reads are significantly more efficient, through reducing the amount of time spent waiting for network I/O.
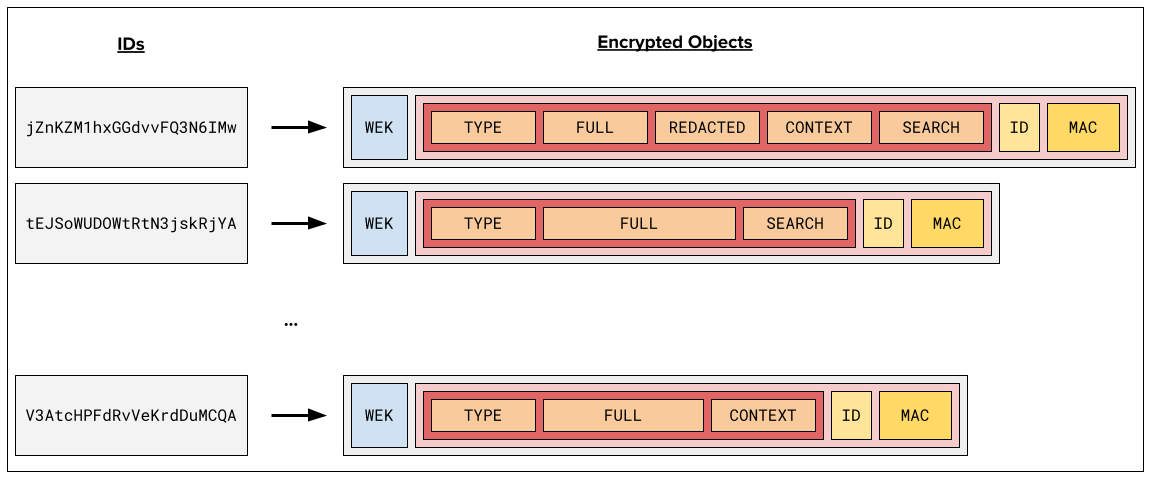
As described in part 1, the objects that HAPII stores have five main properties: a 128-bit identifier, a type, a full sensitive value, an optional redacted value, and an optional search text value. The full and redacted values are represented using type-specific protocol buffers. This affords flexibility in the structure of the values stored, from simple cases like SSNs which are just a single string text value, to potentially more complex cases like addresses that may require multiple properties and nested structure to represent. The full value and redacted value protocol buffers may also be of different types, allowing them to have different representations when necessary.
Objects can also define a "context", represented using a protobuf Struct type, which is similar to a free-form JSON object. We allow this so that objects can hold things like back-references to where they are used, e.g. “This SSN is held for employee X”. This can potentially help avoid the need for follow-up database queries after data is retrieved from HAPII.
Service implementation
The HAPII service is implemented using Kotlin and Vert.x, in order to support our goals of high throughput and low latency request processing, while leveraging the mature toolchains in the JVM ecosystem for stability and maintainability. As HAPII fulfills a similar role to a database, stability and latency guarantees at this level strongly impact downstream services - we therefore want low latency and high availability from HAPII, and a reactive JVM-based stack is a reasonable choice for this purpose.
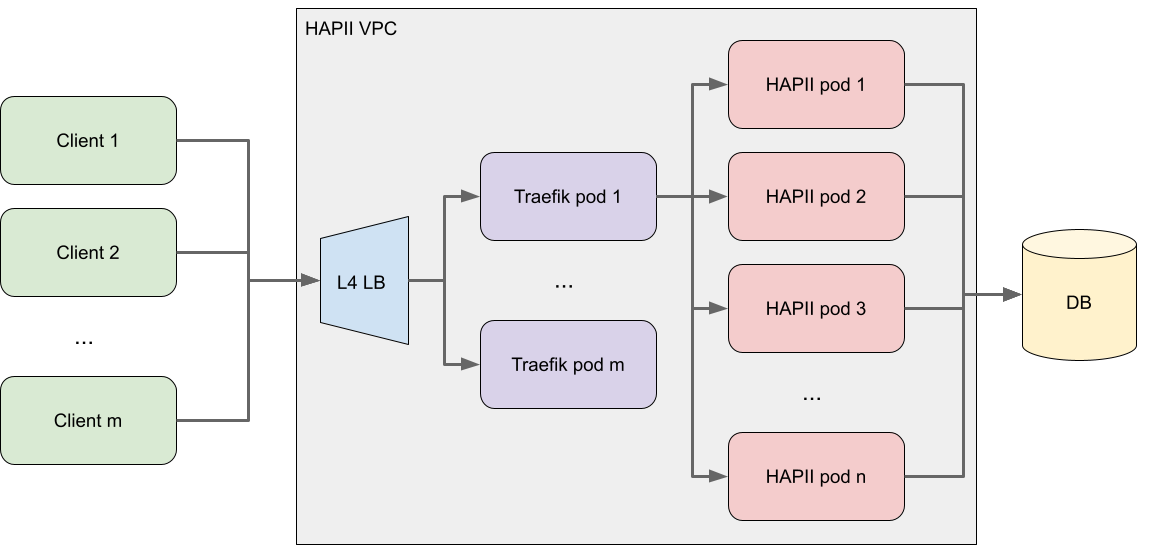
HAPII executes as a stateless, autoscaling deployment of pods in a Kubernetes cluster. A Traefik API gateway is used to load balance requests from clients to the pods. We found this to be necessary as gRPC is HTTP2-based, which many reverse proxies and load balancers are still unable to load balance correctly. In particular, L4 load balancers are a poor fit as gRPC uses fewer connections, and requests are multiplexed into these connections in a way that can result in uneven load across the deployment. With an API gateway like Traefik, which does an excellent job of L7 load balancing of HTTP2 requests, we can ensure much more evenly distributed load across the deployment. An L4 load balancer is used to distribute the client connections across the Traefik pods, where the load of different request types is mostly irrelevant.
HAPII utilizes a MySQL data store for the persistence of encrypted objects. MySQL was selected primarily because it is the database we have the most experience of operating and supporting in production at Gusto, though any robust relational or key-value capable data store could also have been used. We utilize a MySQL implementation with multi region active-passive replication, to limit the risk of losing data in the event of outages or disasters.
Vert.x’s reactive database client was particularly compelling in this configuration. The standard JDBC APIs are synchronous and blocking, and therefore require the use of a thread pool to handle concurrent database operations. While this concern may ultimately be fixed by Project Loom, which will provide lightweight threads for the JVM, this is not yet a stable or widely available. Meanwhile, Kotlin’s coroutines combined with Vert.x’s asynchronous database clients provide for convenient, efficient, and non-blocking interaction with relational data stores.
Storage strategy
Storing data in multiple regions opens additional opportunities for attackers to breach a system and exfiltrate data. To counter this risk, HAPII uses a multi-level encryption strategy:
- Data is encrypted at rest in each database replica using 128-bit keys and AES. The keys are managed by our database provider. This provides one basic layer of defense, is industry standard, and is effectively transparent from our perspective.
- Objects are encrypted prior to writing them to the database, using an envelope encryption scheme - a 128-bit data encryption key (DEK) is generated to encrypt every object with a different key, and this key is itself encrypted using a key encrypting keyset (KEK), a collection of AES 256-bit keys that are shared for the entire data set.
- The KEK is itself encrypted using a root encryption key (REK), which is managed using our cloud provider’s key management system. The encrypted form of the KEK is held in a secrets management system, and delivered to HAPII service during service initialization, decrypted and held exclusively in secure memory. This also has the advantage that communication with the key management service is only required during service initialization; subsequent cryptographic operations are all local to the service and in memory, which reduces latency.

For DEK generation and KEK management, we utilize Google’s Tink library. Tink, similar to libsodium, offers an API for cryptography designed to abstract away complex cryptographic parameters and choices with safe defaults. It also has excellent facilities for keyset management - in fact, both keys and algorithms can be changed easily. If vulnerabilities are discovered at some future date in core algorithms like AES or ECDSA, we will be able to migrate off of these algorithms incrementally, without downtime, or any noticeable impact on our code. In the meantime, we can also frequently rotate the KEK, and rely on Tink itself to interact with our cloud provider’s key management system as needed.
Objects are encrypted using Tink’s support for Authenticated Encryption with Associated Data (AEAD). This technique allows us to securely embed the object ID into the associated data section of the encrypted object in a way that is difficult to tamper with - values cannot be easily swapped between keys, which would potentially allow an attacker to change the behavior of the system. For example, if it were possible to swap or duplicate bank account numbers across keys, it may be possible for an attacker to force funds towards a target account of their choosing. We can prevent this with the use of AEAD - if the associated data to the encrypted object contains the key, and we confirm during decryption that the key matches the associated data, the attacker cannot manipulate the database in this way.
Conclusion
We believe the implementation decisions behind HAPII will help us to reliably use and scale this service as we move more data to this specialized store. We hope you found this deep dive to be informative and educational; if you find HAPII interesting and want to work on systems like this, Gusto is hiring!


