
Over the past year at Gusto, we’ve drastically changed how we approach Sidekiq in our main Rails monolith.
Our changes have reduced costs, reduced the number of outages, made it simpler for product engineers to use Sidekiq, and improved the customer experience.
This blog post will go through the different aspects of our Sidekiq transformation at Gusto.
What is Sidekiq?
Sidekiq is a background job queueing system written in Ruby that uses Redis for storage. It can be useful for sending emails, generating reports, or doing something that is generally too slow to handle in a web request. According to the 2022 Rails Hosting survey, it is the most popular Ruby-based background job framework by a large margin.
Gusto uses Sidekiq, Sidekiq Pro, and Sidekiq Enterprise to handle everything from sending password reset emails to moving a meaningful amount of the US GDP every year on behalf of our 200,000+ customers.
It begins with a pandemic
During March 2020, Gusto and many other businesses found themselves in a precarious position. The western world was shutting down. As credit and venture markets showed signs of slowing, controlling costs became a strong focus for many businesses. Gusto was no exception.
All teams at Gusto were asked to look for opportunities to cut costs. Within our Foundation engineering organization (think: infrastructure, developer experience, etc.), we started investigating different line items in our AWS bill. After a few high-impact, low-effort changes, we found our next-largest line item: the compute resources that powered our Sidekiq experience.
After diving into these machines, we noticed that they were severely underutilized. They were also configured to autoscale but in almost all scenarios the autoscaler would react after the baseline machines would complete a workload.

How did we get here? We had stuck with the recommended Sidekiq approach to name queues things like “critical”, “default”, and “low” for priorities. As our engineering organization grew, each team adopted their own flavors. We saw “payroll_critical” and “benefits_critical”, “payroll_default” and “benefits_default”, and so on. Product engineering teams were in charge of configuring the hardware for their own queues.
Autoscaling up was often fine in the cases where the workload had already finished by the time the scale-up completed. Sometimes though, workloads that were safe to run at low concurrencies were dangerous to run at high concurrencies when it came to overloading our databases with write-heavy workloads. Sidekiq workers scaling up were a contributing factor to recurring partial or complete site outages.
Product engineers at Gusto are tasked with plenty of responsibility at Gusto. While taking a closer look at the queues, we realized this expensive and downtime-causing setup wasn’t yielding the best experience. Different sub-teams had different ideas of what “critical” meant. Oftentimes we’d see important jobs stuck behind backfills or bulk work, resulting in a poor customer experience.

So we had something that was expensive, crash-causing, and inconsistent, leading to a poor customer experience. How did we begin fixing it?
It begins with latency
After a messy experimentation phase, the team landed on a single concept to fix the above issues and turn Sidekiq into an internally managed service. Specifically, organize queues by specific worst-case latency requirements rather than teams and ideas of relative priority.
“Latency” in the case of Sidekiq is the metric derived from “How long has this job been waiting in the queue?” By looking at the next job in the queue and inspecting its latency, we can derive the overall queue latency.
So instead of:
- payroll_critical
- benefits_critical
- payroll_default
- benefits_default
- payroll_low
- benefits_low
We came up with:
- within_30_seconds
- within_5_minutes
- within_1_hour
- within_24_hours
This one idea allowed our team on infrastructure to define an easy-to-understand contract with our partners in product engineering. This interface we stumbled upon wasn’t just randomly selected, it accurately reflected the underlying limitations we would hit when configuring the infrastructure. To quote The Phoenix Project, we “elevated the constraint.”
Each queue’s name represents a worst-case latency expectation for a team. A job will wait in the within_30_seconds queue for up to 30 seconds before being executed. If a job waits more than 30 seconds, a team member gets paged.
We wanted to make adopting these new products as easy as possible, so switching to latency-based queues is a 3-line code change:

Why isn’t every job assigned a 30-second latency?
For the same reason that there isn’t a car that can travel 400 mph, get excellent gas mileage, and still be street legal. Every latency queue has its own set of constraints. Roughly, the amount of work that can be scheduled into a single queue is reduced as the latency is reduced.
Product engineers cannot dump 1 million jobs onto the 30-second queue, since almost any distributed system out there could not handle that load. There’s a good chance that the workload doesn’t need to be done in 30 seconds either. A few hours might be okay. So we ask that product engineers only add jobs to the queue that are short in length (less than a second) and driven primarily by user engagement (someone clicking a button in the app).
As the latencies increase, so does our capacity. We can fit a lot more jobs into a 5-minute or 1-hour chunk of time before we exceed our latency promises.
What if we have a lot of 30-second jobs that are all “well-behaved”?
As Gusto grows, workloads do too. What happens if we have many jobs that are operating within the rules of the 30-second queue but we’re exceeding our latency promises?
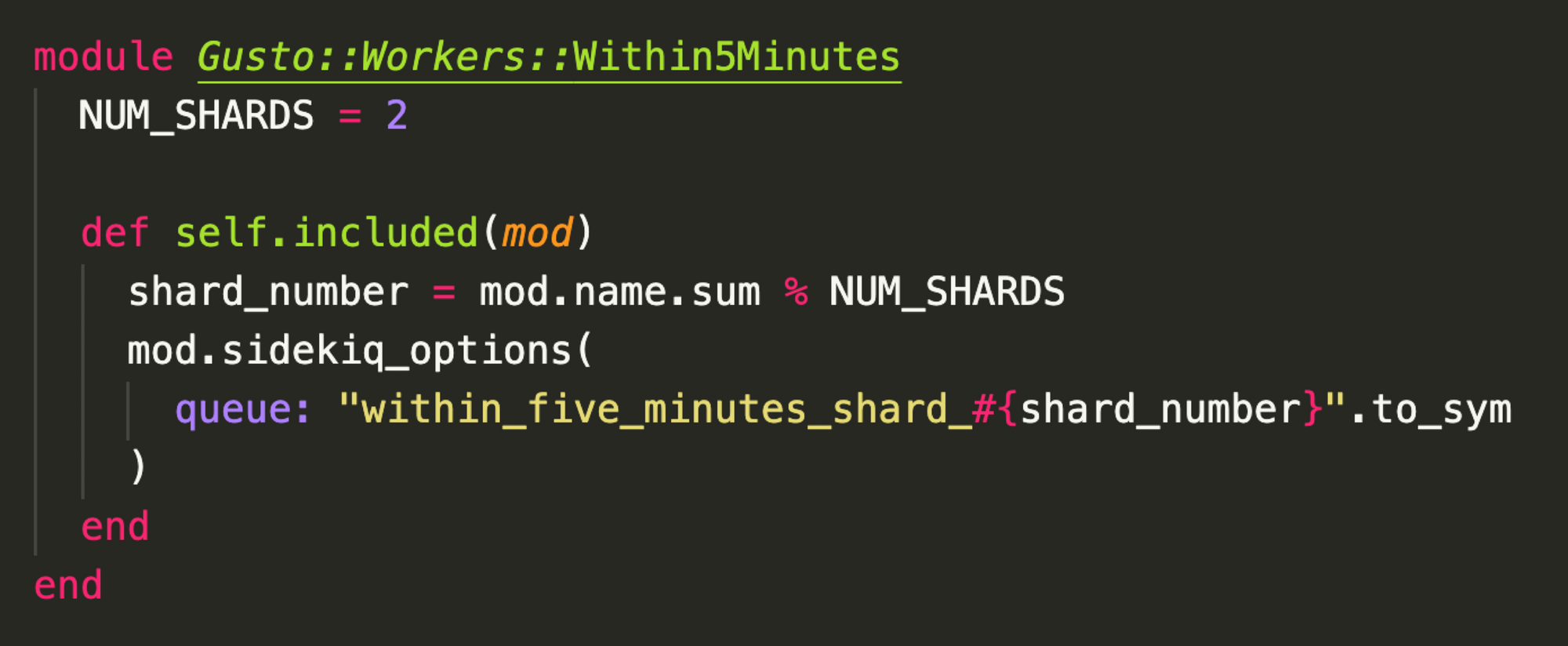
We add a shard!
A point not mentioned from before is that we run each queue at a fixed concurrency without autoscaling. This means we have a fixed amount of machines and threads pointed at any specific queue. We found a fixed concurrency in Sidekiq workers to be the best protection for database overloads.
So if we have 10 processes each running 10 threads (something we call “10x10”) for a single queue, we’ll add another 10x10 shard.
From a Sidekiq perspective, that means we go from:
- within_30_seconds
To:
- within_30_seconds_shard_0
- within_30_seconds_shard_1
Because we don’t want any one job to run at too high of a concurrency, we choose a shard based on job class name. This crude approach means the workloads are not perfectly balanced (i.e. 50/50), but they are safely balanced. Given this approach, we can add new shards to increase throughput for the 30-second latency promise as much as we need.
Here's how we implement that in code:
At the time of writing, if a job is exhausting a 30-second queue shard, we will create specialized infrastructure for that single job or work with the team to optimize that particular job.
Does every job fit in a latency queue?
As of the time of writing, 93% of all jobs within the main monolith run on a latency-based queue, but not all jobs fit that paradigm. For example, some jobs are so critical to the system that we don't want other jobs to share a queue with them, so we create "express lanes" for those jobs. We also have a few jobs that have been stubborn to refactoring. One day we might get to those last few…
What about workloads that need a higher concurrency?
While most workloads run at a fixed concurrency to protect downstream services like our databases, there is a category of work that benefits from and is safe to run at high concurrency. These workloads are entirely read-only from the perspective of the databases. By connecting to read replicas, we’re able to safely scale the concurrency to much higher levels.
To accomplish this, we use a Sidekiq server middleware to wrap the entire job’s execution in a ActiveRecord manual connection switch block. In the case where the job attempts to write to the database, we gracefully re-enqueue the job onto a read/write queue.
The result is something that is not only performant but safe. This escape hatch into performance allows teams to restructure their jobs to take advantage of this safe high concurrency. Teams will sometimes split jobs into read-only pre-work jobs over a large dataset to filter down to a small set of read/write jobs.
What are the results?
Completing this project required inspecting every Sidekiq job within the main monolith and asking “What’s the best latency for this job?” After about a year of work and nearly a dozen people involved, we can proudly claim the following:
- Sidekiq infrastructure costs have decreased 40% while Gusto’s customer base continues to grow.
- Latency queues with their fixed concurrency have yet to cause a partial or full site outage.
- The customer experience is more consistent, with workloads happening by a certain time or an infrastructure engineer getting paged.
- Product engineers can spend more time focusing on the product and less time configuring hardware, which helps differentiate Gusto and make the best use of a critical resource (our time!).
Further Reading
- Sidekiq in Practice by Nate Berkopec
- Sidekiq Best Practices from the Sidekiq Wiki
