A method for simplifying large monoliths
Entropy is a universal law: everything tends toward disorder without reinvested energy. Software is no exception. When evolutionary development is constrained by time and/or budget, systems become “monolithic”. That’s often a euphemism for spaghetti of inconsistent abstractions.
Gusto has been building Payroll software for over a decade. We now serve over 300k businesses nationwide. The abstractions we started with have grown along with our customers’ needs. Not to mention ever-evolving government & compliance requirements. People spend years becoming expert payroll professionals.
Ideal engineering balances requirements & constraints: solve necessary complexity, but simply, quickly, efficiently, and accurately. The resulting tradeoffs are universal in software growth, and even life: minding the future too much, or not enough. Both extremes are costly. Perfection protects the future but costs time & money, and is risky besides: the future is elusive & ever-changing. Speed protects the now but risks unnecessary complexity or even rework as we add features.
Let’s explore that tradeoff, and how we get to monolithic software in the first place. Then we’ll talk about a method to find simplifications in a complex system. We’ll use Ruby on Rails ActiveRecord abstractions as an example.
Tradeoffs in unnecessary complexity
Unnecessary complexity is quite costly at scale. It makes the system harder in every respect: development, debugging, operation, planning. Yet it’s very persistent! Why? Sandi Metz wrote about this in The Wrong Abstraction (2016). Our unconscious biases push us to treat large systems with undue deference:
Existing code exerts a powerful influence. Its very presence argues that it is both correct and necessary. [...] the more complicated and incomprehensible the code the more we feel pressure to retain it (the "sunk cost fallacy").
But there’s no particular reason to put code on a pedestal. Prototypes have a way of staying in production; it’s easy to approximate, or even misunderstand complex domains. Frankly, software architecture is just hard. So is running payroll. Everybody makes mistakes.
It’s hard to justify investing in refactors when we struggle to even articulate the problem & solution, aka cost & benefit. There are explicit and unconscious pressures to build new features within the system rather than change the system. But, again per Sandi Metz:
Attempting to [build within the system], however, is brutal. The code no longer represents a single, common abstraction, but has instead become a condition-laden procedure which interleaves a number of vaguely associated ideas. It is hard to understand and easy to break.
The more this plays out, the more the software deviates from the ideal. Let’s assume we can quantify quality from 0-100%. To be clear: we can’t actually quantify quality like this, but it’s a helpful metaphor.
Due to budget constraints etc, we might accept getting it less than perfect– say, 97% perfect (according to our fictional metric). The primary requirement is to get it right for the customer, while safeguarding engineering & business efficiencies. It may sound innocent enough to do this once or twice. But if we repeat this decision 45 times, we end up at 25% of the ideal. If we get it 99% ideal, it takes 137 repetitions: more, but not that many over a decade of software development.

These pains are normal and even necessary: navigating imperfection is part of software development, and, well, life. But as engineers, we need to keep this compounding effect in check. How? Sandi Metz proposes duplication to reduce the coupling: inline abstractions into callers, then derive new abstractions. Fully inlining the abstraction into all call sites effectively erases it. Then,
Once you completely remove the old abstraction you can start anew, re-isolating duplication and re-extracting abstractions. [...] Once an abstraction is proved wrong the best strategy is to re-introduce duplication and let it show you what's right.
This is incredibly valuable advice: let the code itself reveal the abstraction. Maybe Marie Kondo would refactor software this way: take everything out of the abstraction closet, lay it out on the floor. Then keep what sparks joy, and discard the rest.
Well, two problems. First, most production systems can’t just drop code that doesn’t “spark joy”. Second, pulling things out of the closet without reorganizing them is entropy: everything sprawled about. The result is a pile of lego pieces linked to each other, not repeated patterns. It’s like discussing apples in terms of their atoms, or worse: quantum quarks…

But how to organize a pile of legos? Maybe by color or shape. But legos also come in specialized kits, themed as castles or starships. Maybe organize by theme first, then color? Wait… why are we talking about legos again?
Organizing legos is effectively a data indexing abstraction. Organizing by color first makes it harder to find the pieces to a specific kit. But organizing by kit first makes it harder to find unusual shapes unless we also track which shape comes from which kit.
For our payroll software, do we organize by domain like pay or taxes? By tech stack like Ruby or Javascript? The natural Rails organization is grouping together: API controllers; view layouts; utility services; ActiveRecord models; and so forth. But feature changes typically affect several layers together.
The ideal organization optimizes for today’s work, not yesterday’s.
Tomorrow’s work is important insofar as reorganization is expensive or risky.
In a large software system, today’s work is a lot of work. Necessary domain complexity always comes with unnecessary, accidental complexity. If it were easy to create a “Grand Unified Abstraction” we’d have already done it (probably).
Why’s it so hard to create these grand unified, 100% abstractions? Well, Mark Twain is said to have written a long letter because he didn’t have time to write a short one. Indeed: it’s quite a feat to convey lots of information, while combining accuracy, brevity, and clarity. Twain’s witticism dates back to the French philosopher Blaise Pascal in 1657:
Je n’ai fait celle-ci plus longue que parce que je n’ai pas eu le loisir de la faire plus courte.
My translation: I only made this [letter] longer, because I didn’t have the leisure of making it shorter.
So to mix these metaphors: we need to organize the lego pile, and it takes time to organize it well. Errors are inevitable. That’s why we say: don’t let perfect be the enemy of great. But we also say that action without vision is a nightmare. Just “doing something” isn’t necessarily valuable: just like scribbling a few words might not communicate that much.
Let’s say that our “vision” is that abstract 100% from earlier. We know that targeting 100% isn’t pragmatic. As Gusto engineers we need to build for our customers quickly, and also safely. We also need to keep our business nimble over the long term: progress today should not stall progress tomorrow. As a staff engineer, helping strike this balance is one of my top responsibilities.
We also know that organizing 1,000 legos begins with sorting 1 piece. But a single piece is not a representative sample. Nor is even a handful of pieces. Imagine our system indexed 1x1 and 4x2 blocks, and grouped the rest into an “other” basket? Well that sounds like a nightmare… unless 1x1s and 4x2s are all we need.
In software terms, you may have seen local refactors that somehow don’t change overall system complexity. This is like simplifying API implementation without changing the API design. Or like, making local maxima more locally maximal. In the abstract, these refactors are “no regrets”: better is better right? Yes, but factor in the opportunity cost: more effort here means less effort there.
As systems grow and complexities abound, the problem becomes urgent. My Payroll teams ask ourselves which architectural changes are actually worth the refactor cost. After all, these refactors are hard to estimate. The whole problem with complexity is that it’s hard to understand, communicate, and therefore predict.
Despite these challenges, the graph above makes clear the cost of always getting it even 99% right without ever reinvesting. As systems scale, refining system architecture is less luxury, more necessity. The ideal refactor balances:
- selected use cases, to not morph into “fix all the things”
- sufficient use cases, to not morph into local over-optimization
Targeting all use cases–fixing all the things–means progress can’t be made unless it’s global. But fixing too few doesn’t capture abstractions. Following the 80/20 Pareto Principle, we decided 80% was a good balance to target. We found patterns that apply to 80% of the use cases and rebuilt our Payroll abstractions from there. Whatever’s happening in this 80% must be very core to the domain, as it appears in so many places. Everything else is … something else, that we can worry about some other time. But organizing 80% rather than 100% is still very impactful.
Rearchitecting our system for its specific problems today reinforced our payroll platform. It unblocked capabilities we expected, and continues to provide unexpected benefits. That’s the whole point of good abstractions: more people can create software quickly and safely.
Example: ActiveRecord aka data modeling
Gusto’s server tech stack is almost entirely Ruby on Rails, so of course we use ActiveRecord. Something about Rails seems to inevitably produce “monolithic apps”. Why? Well, ActiveRecord is a powerful abstraction. Too powerful: over time, ActiveRecord models become “the” API into the data. All application use cases funnel through the same models. All use cases are exposed to each others’ concerns. Safe changes require understanding the implicit and explicit connections between data. When it’s hard to use the data model safely, chaos ensues!
Here’s a classic example. Let’s say we’re building a brand new payroll system and our data model has three columns: Date, Hours, and Pay. It looks something like this:

We quickly realize we need to handle taxes 🤦 But, we only know the taxes once we’ve computed the payroll, or run it as we say. We add two columns: a boolean flag run? and, if true, a filled-out taxes column. If run? is false, the taxes column is meaningless. So the new data model looks like this:
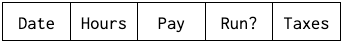
Now, Payroll rows aka ActiveRecord objects come with two new columns run? and taxes. This is fairly harmless when the system is small enough to fit in memory–human memory, that is. Two problems:
- a new team member, by definition, does not have this memory (yet)
- the system gets bigger than human memory, quickly
I’ll leave it to the imagination to find additional flags, new columns, or enum states we might need to represent a full payroll system. We also typically don’t store lump sums like pay... we break it out into itemizations on another table. Payroll’s super complex: it gets real interesting real fast.
But for the purposes of this blog, we’ll stick to an abstract row with columns. Abstraction is great! Recall that Sandi Metz said “bad abstractions” represent:
a condition-laden procedure which interleaves a number of vaguely associated ideas
Therefore a ‘better’ abstraction:
- has fewer conditions
- groups similarities, separates differences
Since we’re focused on the data model layer, let’s start simple: what data is used & how? Here we’ll consider read-only use cases like filtering rows by some condition & reading column values. This isn’t a costly simplification by the way. In many domains, most software is about displaying or reporting on data more than changing it. We’ll start with five not-so-hypothetical use cases for payroll software:
- Review total hours worked in a month.
- Display pay stubs for a check date.
- File quarterly taxes.
- Audit employee benefits.
- Summarize final pay while drafting a payroll.
First we need to figure out how these use cases select rows, and what they do with them. Not so easy: we’re here because of “bad abstractions”. So this step is actually navigating the mysteries of the monolith. Sometimes, we can see the patterns without actually duplicating out the abstraction; sometimes, duplication is really beneficial to see it all laid out.
In our case, the use cases might boil down to these steps:
- Total hours worked: select run payrolls for the month, then sum hours across those payrolls.
- Pay stub: select run payrolls on the check date, then display the date, hours, & pay.
- Taxes: select run payrolls for the quarter, then aggregate the pay & taxes fields.
- Auditing: select run payrolls with benefit pay greater than zero 0, then return the dates.
- Draft payrolls: select payrolls for the pay date, then sum pay for the draft & processed groups.
The English repetitions suggest the patterns. But nothing beats a visualization! I’ll use the following colors; blue for reading a column, yellow for filtering, and violet for both reading and filtering.
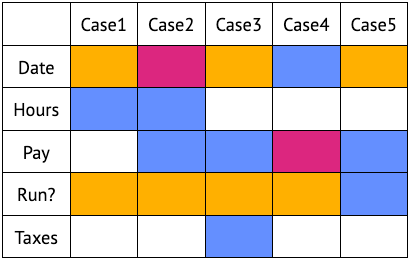
Here’s a few observations from this visualization:
- All use cases care about dates. In most cases, we’re selecting data for a time period.
- All use cases care about run status. But ⅘ of cases just filter on the run field then forget about it. Draft data isn’t “real” for these usages: as far as they’re concerned, there’s no such thing as draft data.
- Only ⅕ of use cases read taxes. Are taxes the exception? This is a good time to check for sample bias. Still, in the spirit of grouping similarities & separating differences, this suggests that time & taxes might benefit from separate abstractions.
- Most use cases care about pay, but only some care about time. As above, this suggests pay is the primary concept in these use cases. Indeed for employees, time is typically the main input to pay. Once we’re done tracking time, pay is the real-world consequence.
As if by magic, 80% of use cases only care about “real”, processed data. In a large payroll system, the actual number would be much higher: of course we only care about facts that happened. On the other hand, dealing with draft data is part of a core payroll function: running payroll to get employees their paychecks. Yet for a draft payroll, the data is, effectively, real. If it weren’t real to the use case, we wouldn’t bother with it.
The whole point of abstractions is to separate implementer & consumer concerns, right? In that view, this near-total split of draft & run payrolls suggests that run payrolls are the consumer’s concern; draft payrolls are the mechanism to generate new processed payrolls.
What can we do with this insight? We can’t just remove run? from the database, not unless we split out draft & run payroll tables (but that has other implications). But we can make sure people don’t need to care about it unless they have to.
Remember, our monolith is so big and our teams changing so fluidly, it’s not as simple as just “remembering” whether it matters. The one column run? becomes a combination of flags; then these flags become a combination of enums spread across several joined rows aka associated ActiveRecord object graphs. In any case, the ideal abstraction provides this guarantee:
I see it ⇔ I care about it
Or, to borrow the classic 2x2 matrix abstraction:
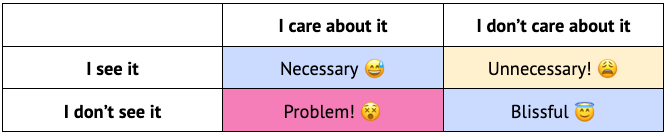
Avoiding the worst–actual problems–is how we end up with ever-growing abstractions. Sometimes you have to complicate instead of stagnate. But unnecessary complexity becomes overwhelming. So we need that sweet spot: as much complexity as necessary, but as much blissful ignorance as possible.
One way to achieve this is by isolating complexity to the point of fetching data. From that point on, all downstream consumers should be blissfully ignorant and assume the data was selected appropriately. Rather than an API like this:
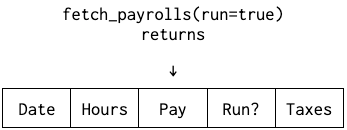
We’d have two APIs:
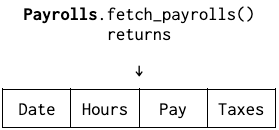
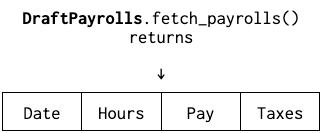
The naming enshrines that run payrolls are the real ones for most intents and purposes, and drafts are the exception. But in both cases, we just have payrolls.
In a large software system, iterating this process over several layers reveals the “80% abstractions”– ones that are good enough to meaningfully impact the system, but don’t try to be perfect.

It’s better to organize things that would obviously benefit from organization, even if that means a monkey plushie sneaks into the lego pile because we don’t know what to do with it. The perfect organization will be expensive & risky to build. But the other way leads to the proverbial nightmare of action without vision.
At Gusto, we put this method to practice, introducing payroll tax data abstractions. Starting from Dillon Tiner’s analysis of tax use cases, we developed a new tax liability API. This API became the basis for Tori Huang’s work to increase precision & granularity of our tax correction system. In the process, this abstraction largely decoupled our filings system from our payroll tax data. But this is another story for another day.
Duplication to unwind bad abstractions is a powerful tool for growth. Just make sure to pare it back, recognizing that accomplished 80% is far more valuable than failed 100%.
Thanks to Tori Huang, Glen Oliff, Alyssa Hester, & Lynn Langit for their review. Special thanks to Tori for the “80% abstraction” work we did and co-presented to Gusto Engineering: without all those discussions & subsequent edits, this piece wouldn’t exist. Special thanks also to Lynn for her mentorship & encouraging my writing for nearly a decade!

