How optimizing for learning helped us scale to 1% of small businesses in the US
“Your vision is great, but it's all about execution.”
If you’ve worked in startup environments or have tried to raise money for one, you probably heard this stated in some way, shape, or form. There are seven billion people in the world and it's quite likely that several other companies have already thought of your vision, tried to execute on it, and failed. Companies may have failed to deliver on your vision for a variety of reasons unrelated to execution. But for all companies starting under the same market conditions, execution -– the ability to make your vision into a reality –- is the key differentiator.
As an engineering, product, and design (EPD) team, we strongly believe that our ability to execute on our vision is one of our key competencies and has fueled our success to date.
So what is execution? And how do we judge what it means to be good at executing as an EPD team?
To be good at execution as an EPD team we must:
- Continuously identify the next most important problem we should be solving for our customers. We’ve written about this in the past.
- Understand (roughly) the cost and benefit of solving the problem, and our confidence level in both side of the equation.
- Find the optimal set of tradeoffs between product scope and engineering costs in solving the problem.
Why shipped software can be the wrong metric of success
In its most basic form, the Agile process focuses on shipping working software in close collaboration with customers. Teams are encouraged to ship incremental product value every sprint, and there’s some amount of guilt associated when sprints end with less than 80% of the value being shipped as production code.
The motivation behind this focus is quite logical: getting working software in the hands of customers tells us what value they get out of it. If the value they get from it doesn’t meet our initial hypothesis, then the return on investment for this project is lower than anticipated and we can stop working on this problem and go back to step one and identify the next problem. While this process makes sense in specific contexts, to get really good at execution and find the optimal path, we need to look a lot more closely at a few other dimensions and vary our process accordingly.
How to know when your Agile process is suboptimal
The two dimensions we focus on initially is our confidence level in the cost and value of the project. This sets the tone for the type of methodology we’re going to use to tackle the problem. The confidence level can be derived in multiple ways, but usually the most telling sign is to pay close attention to the team working on the project when they’re first being asked to tackle the problem.
“This is either a one-week or a 6-month project,” one engineer would share, as they’re contemplating all the possible ways the implicit assumptions in our intentionally ambiguous and low-fidelity problem statement will blow up as rubber meets the road. “I worry that if we built it, customers won’t get the value we think they’ll get,” another engineer would share as they’re calling upon all the tacit knowledge they’ve built over the years about our target customer, and specifically remembering one support call they shadowed when one customer didn’t express any need for this.
The high variance in the team’s assessment of the project and the sense of worry, or lack of both, is our “sniff test” for the project.
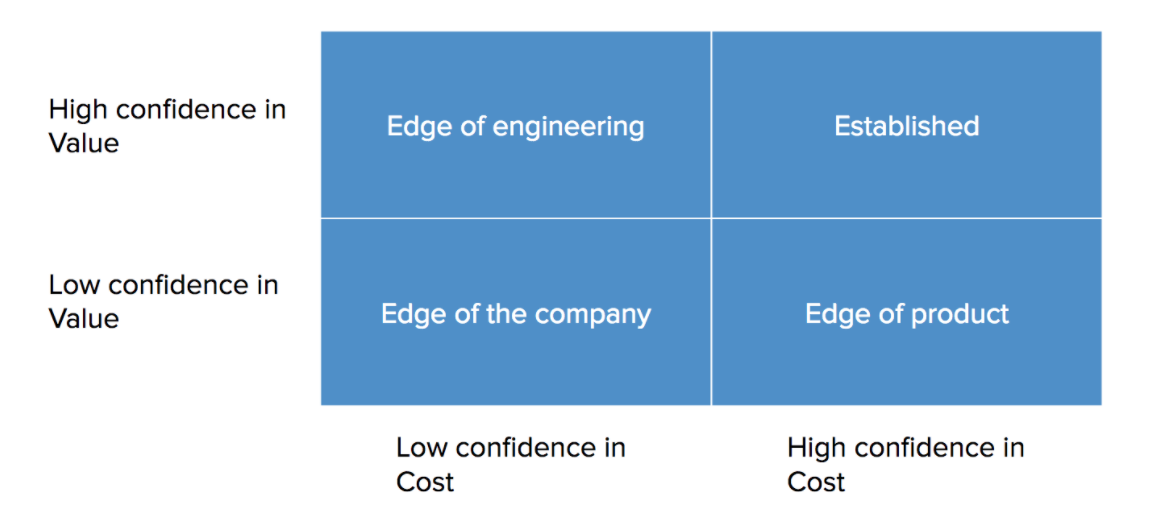 What’s the distance between the problem space and the edge of the company?
What’s the distance between the problem space and the edge of the company?
-
High confidence in cost, high confidence in value: Projects where we have high confidence in their cost and value are core to what we do as a company. When we extend our payroll product to support a new electronic data exchange with a tax agency, we know exactly the value it provides to our customers and what it would take for us to do so because we have honed that muscle. This is an area of the company where our business is already established.
-
High confidence in cost, low confidence in value: Projects where we have high confidence in their cost, but low confidence in its value to customers, are at the edge of our product offering as a company. Even though they present no technological challenge, because it's “yet another feature” on the current tech stack which we’ve used for years, there are question marks around the customer demand. This is an area of our company where our business is venturing beyond of our established product offering.
-
High confidence in value, low confidence in cost: Projects where we have high confidence in their value, but low confidence in their cost, are at the edge of our existing tech stack and/or code base. These can be on the more obvious extreme side — “our first machine learning attempt at automating what we do today with humans and has proven to be successful” — but more often than not they’re much subtler. For example, you might be iterating on your core data model which made a one-to-one assumption between two entities and now you’re changing it to one-to-many, but that could fundamentally change how many other parts in your system works. This is an area of our company where “the how” of solving a problem is venturing beyond our established code base or the team’s experience with the technology.
-
Low confidence in cost, low confidence in value: Projects where we have low confidence in their cost and value are at the edge of everything we currently do as a company from a product and engineering perspective. These present the most risk, which makes them even more exciting.

Lose the hammer, go for the swiss army knife
Once we understand the context, we then look to truly understand whether basic Agile process is our tool of choice. In our experience, it works best only when you have high confidence in cost and low confidence in value. The optimal thing you could do to get to high confidence in value is ship software iteratively so that you can test your hypothesis with customers in production and get feedback as soon as possible. When we’re working on a known quantity, we keep process to a minimum because frankly, we don’t need anything else other than a to-do list to get it done.
For projects with low confidence in cost, we amp way down the focus on shipped software and we focus exclusively on a process to journey us through the Dunning Kruger curve.
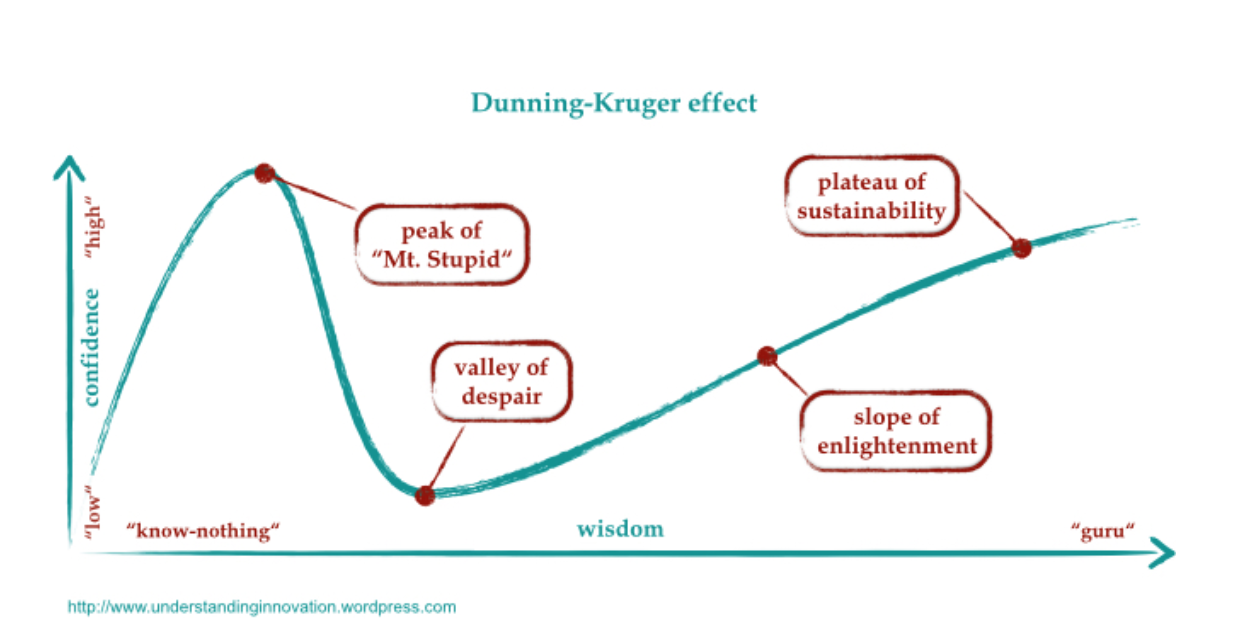
Project Kickoffs
At the kick-off of the project we do many throwaway technical spikes and code experiments until we feel confident we’ve hit the peak of “Mt. Stupid,” followed by the “Valley of Despair.”
In the previous example of the data model change, this could mean something as simple as to change the semantics of the entity relationship to one-to-many (Why would this be hard? It's a one-line code change), and seeing how many tests break if we ran our test suite and how many errors would happen if we took production data and tried to exercise the codebase against it.
The goal is not to answer any important questions of how we’re going to make this change but rather, what is the surface area of the blast radius from making the change.
A good sign to know if you’ve reached the “Valley of Despair” is when the number of things on your backlog of “things you need to think about” has multiplied by five to ten.
The good news, there’s no way but up from here.
Reaching the slop of enlightenment
“Maximising the rate of learning by minimising the time to try things.” — Tom Chi, co-founder of Google X
To start making our way up the slope of wisdom, we focus on identifying the smallest yet complete set of code experiments that will provide us with confidence in our abilities to solve the problem and at what cost, separating proof from optimization.
At the heart of a steam engine, is the fundamental ability for steam pressure to push a piston up and down, regardless of how efficient or inefficient this engine is in converting 100% of the steam energy. Similarly for code, we focus on identifying and proving feasibility for key questions.
These vary based on the type of the problem, but for instance, when integrating a new third-party API, we might ask ourselves:
- Does this API’s authentication and authorization capabilities meet our needs?
- Can we orchestrate all needed behaviors?
- Are we able to correlate the API’s incoming asynchronous error events with their original requests? If so, using which data elements?
This is inherently different from writing standard production code, which could add a lot of other elements to the development process such as integrating with existing systems like a production credentials vault, exceptions and log tracking systems, working with longer continuous integration cycles, etc. While these are critical for the optimized version of the API integration, they provide no value in learnings and increase iteration time in trying things.
The real special sauce is in the side effects
By kicking off a project (which undoubtedly is very exciting given the uncertainty or potentially anxiety-inducing in a good way if you’re more on the anxious side like me) with the Part 1 loop, the project team builds deep context into the problem space in an accelerated time frame.
Key dependencies and assumptions are put to rapid tests and no implicitness is left uncovered. We rally broad team support for decisions early on by deliberately “going down the rabbit hole” of the major decision points at the projects start, which paves the way for minimal rehashing of decisions being revisited.
By substantially reducing the cognitive overload of uncertainty early on, we create an abundance of clear headspace to focus on delivering a delightful product at our high standard of code quality, without the constant “well, what about…” chipping away at focus.
Try it with your team!
Deliberate retrospectives
“What could we have learned faster this week given what we knew at the time?”
This question encourages the team to constantly evaluate the iteration cost they’re paying to learn new things, and specifically moves away from learnings based on what we know now. Hindsight is always 20/20. We want the team to develop better judgement about decisions they took given the information they had at the time, and not what we know today. This gap in decision-making judgement is your success criteria. If you’ve hit zero, you’ve made it!

Bake uncertainty into planning
Focus estimates on a range of outcomes.
There are many ways to bake uncertainty into your planning process. One simple tactic we use is range estimates based on best/expected/worst. If you break down your project plan into a list of line items for “things you need to figure out and/or build” and keep each line item’s estimate to no longer than a week, it shouldn’t take very long to break down each line item.
Doing so will give you a “heat map” of where your biggest unknowns are, as well as a great opportunity to have conversations with your stakeholders on the tradeoffs between scope, costs, and assumptions.
Embrace risks throughout the project
Normalize talking about the worries, risks and unknowns.
Kick off the project by asking:
- What are we most worried about?
- What are our biggest risks?
- What are our biggest unknowns?
- What are the cheapest ways for us to mitigate risks and increase our confidence level?
Write things down
Ambiguity is better stored in documents than people's minds.
Write down all the unknowns the team needs to follow up on. The tricky thing about ambiguity is that it can create high cognitive overload, which can get in the way of forward progress. Having a single place where all questions are captured, as well as when we need answers by before we’re blocked or slowed down, is a great way to combat that and also help your product team and stakeholders prioritize what they should look into next based on its time sensitivity.
If you’re passionate about the craft of getting things done, come join us, we’re hiring! We’ve developed a specialized career track we call “Technical Anchor” for engineers who are interested in leading other engineers in getting things done.
About the author
Omri is a Software Engineer from San Francisco. Omri empowers engineering teams at Gusto and is passionate about lean product development processes. He hates wasting calories on bad food and loves making bad puns (to his team's chagrin).
